也不是笔者不想写完,主要有点忙()
MISC
1-1签到
直接公众号回复关键字即可
1-2 隐藏款球星卡
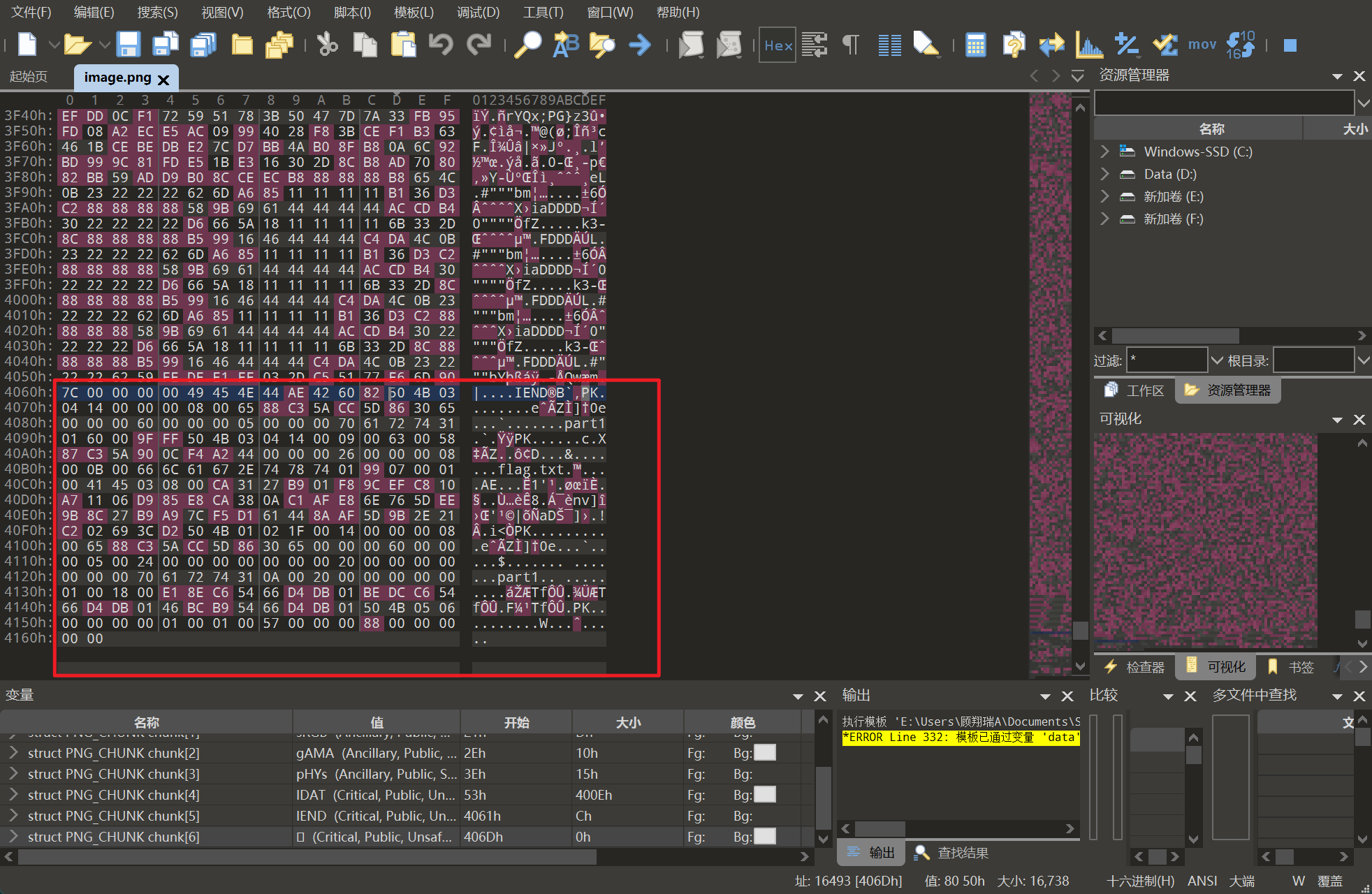
附件中的三张图解压出来,在010中查看末尾发现是三段base64编码,解码出来获取加密的密码
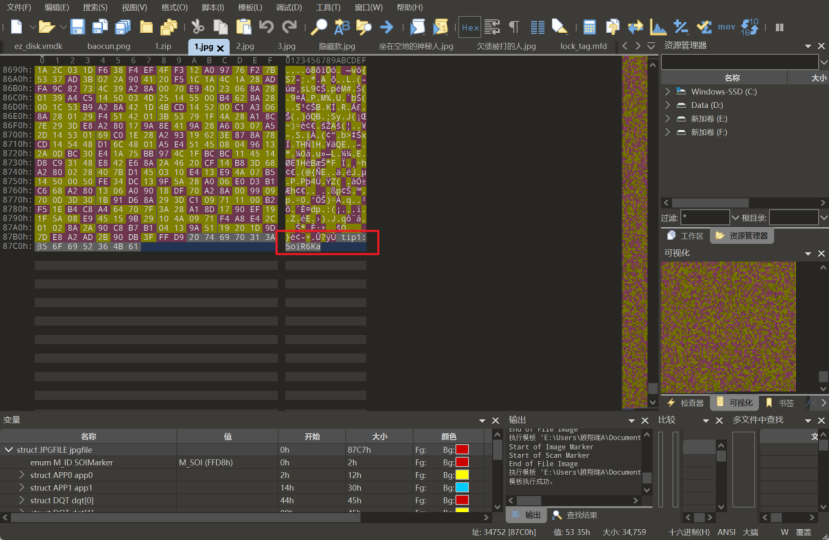
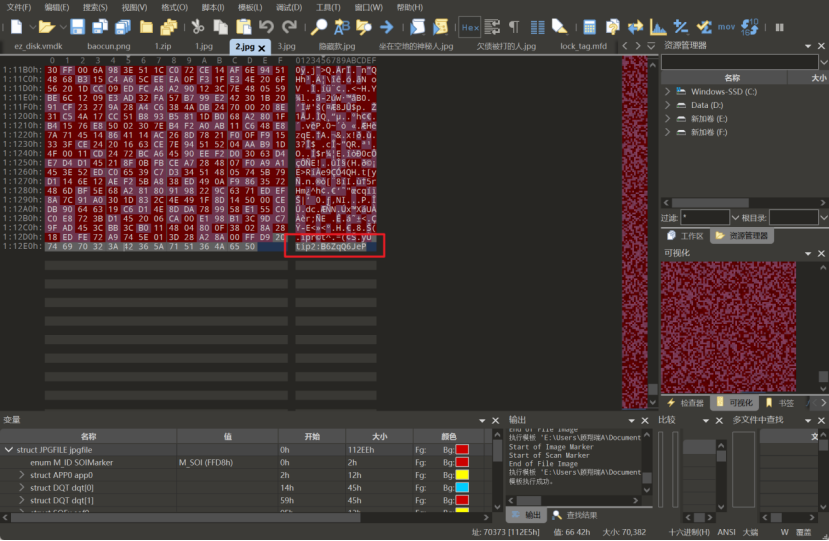
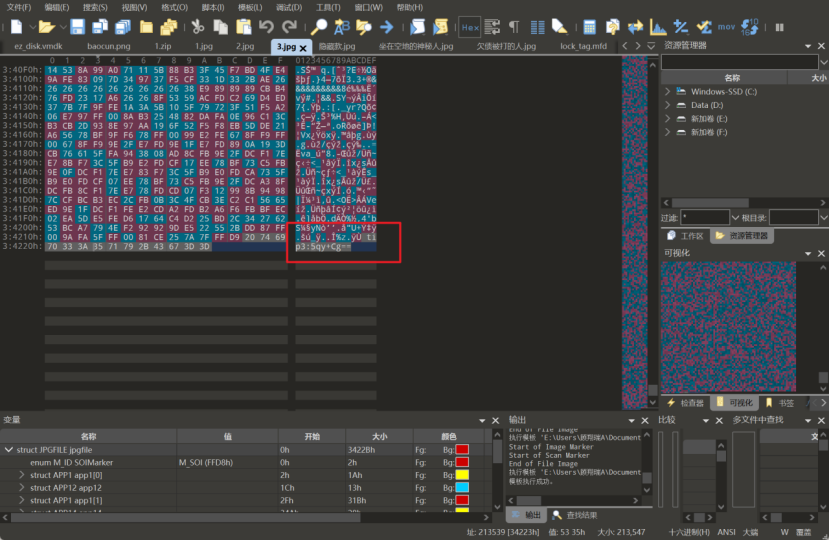
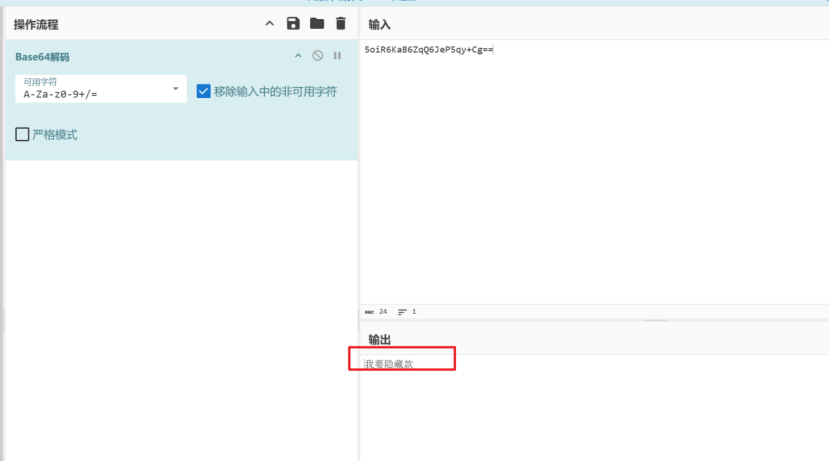
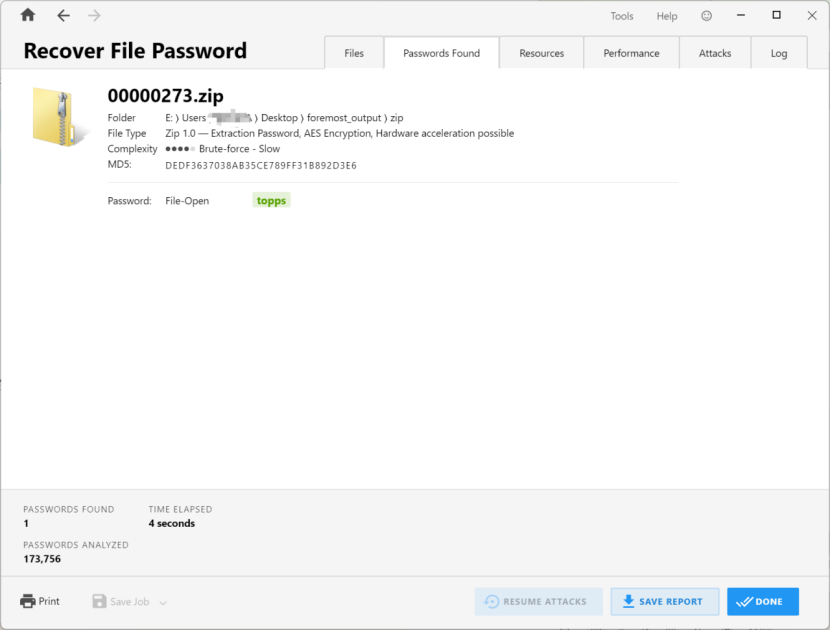
解压出图片后在图片末尾存在压缩包,foremost提出来带加密,passware kit跑字典出密码为topps
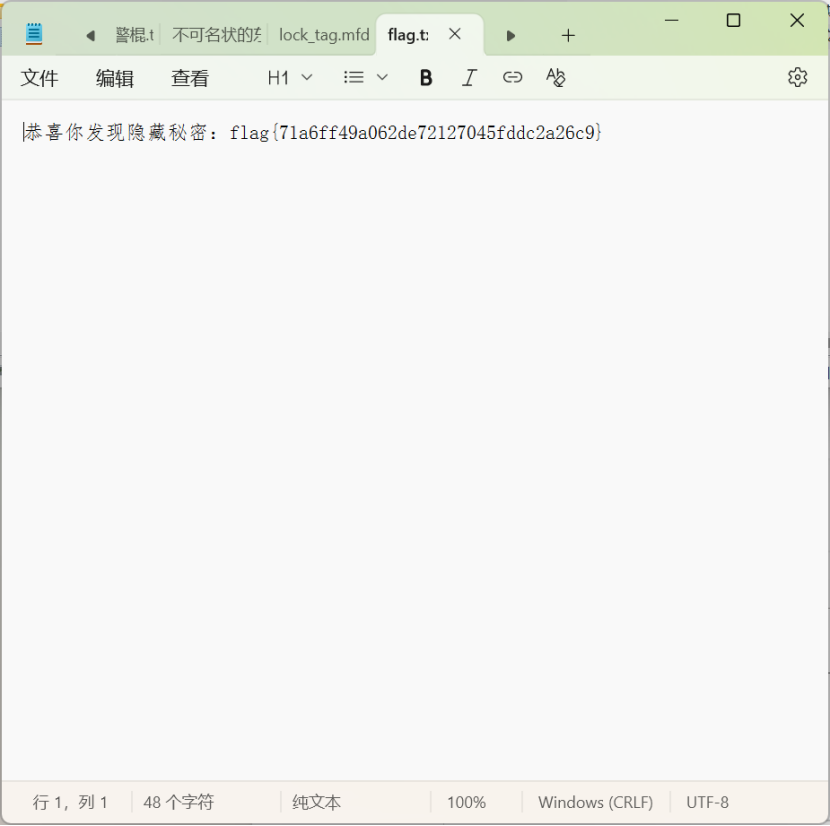
得到flag:
1-3 神话传说
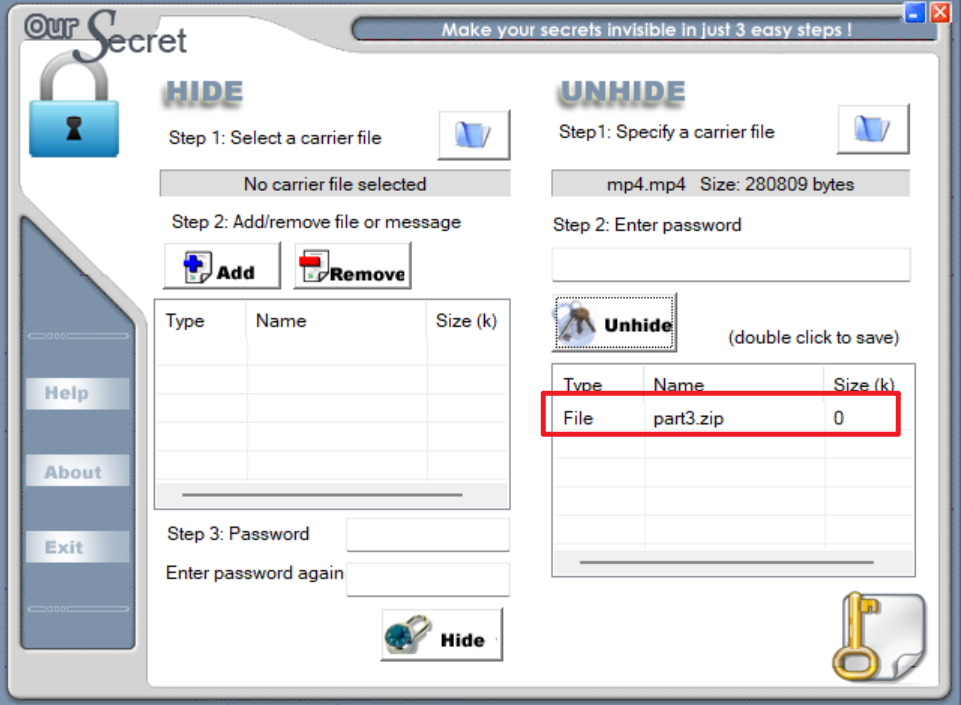
拿到附件,有一个mp4和hint,hint是base100编码,直接接出来是一个key,MP4的隐写的话按照经验一般就只有oursecret和隐写者两个工具,而隐写者本质上还是给后面直接加上的压缩包,改后缀就能处理,而用010打开查看可以发现有oursecrt的特征
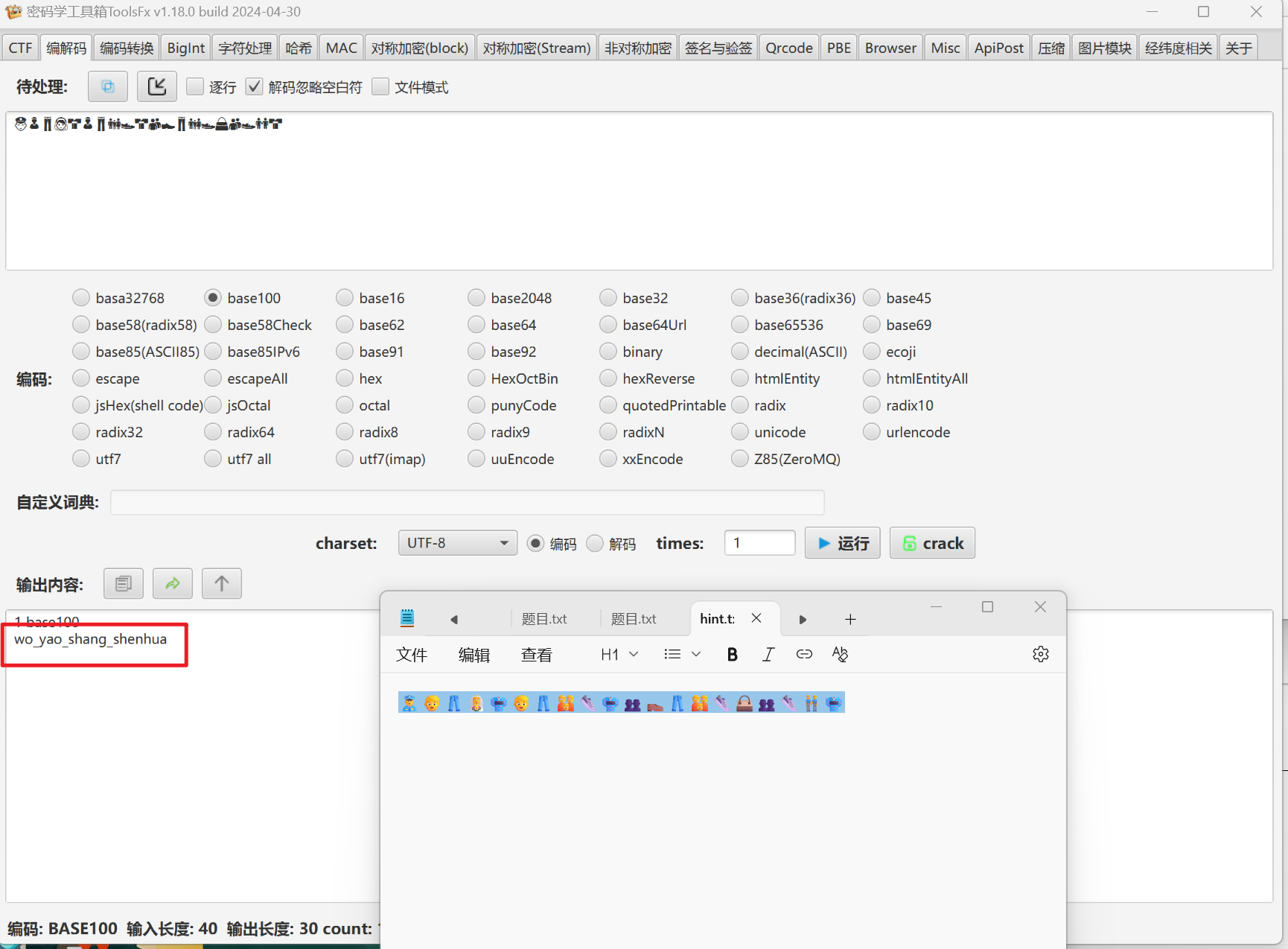
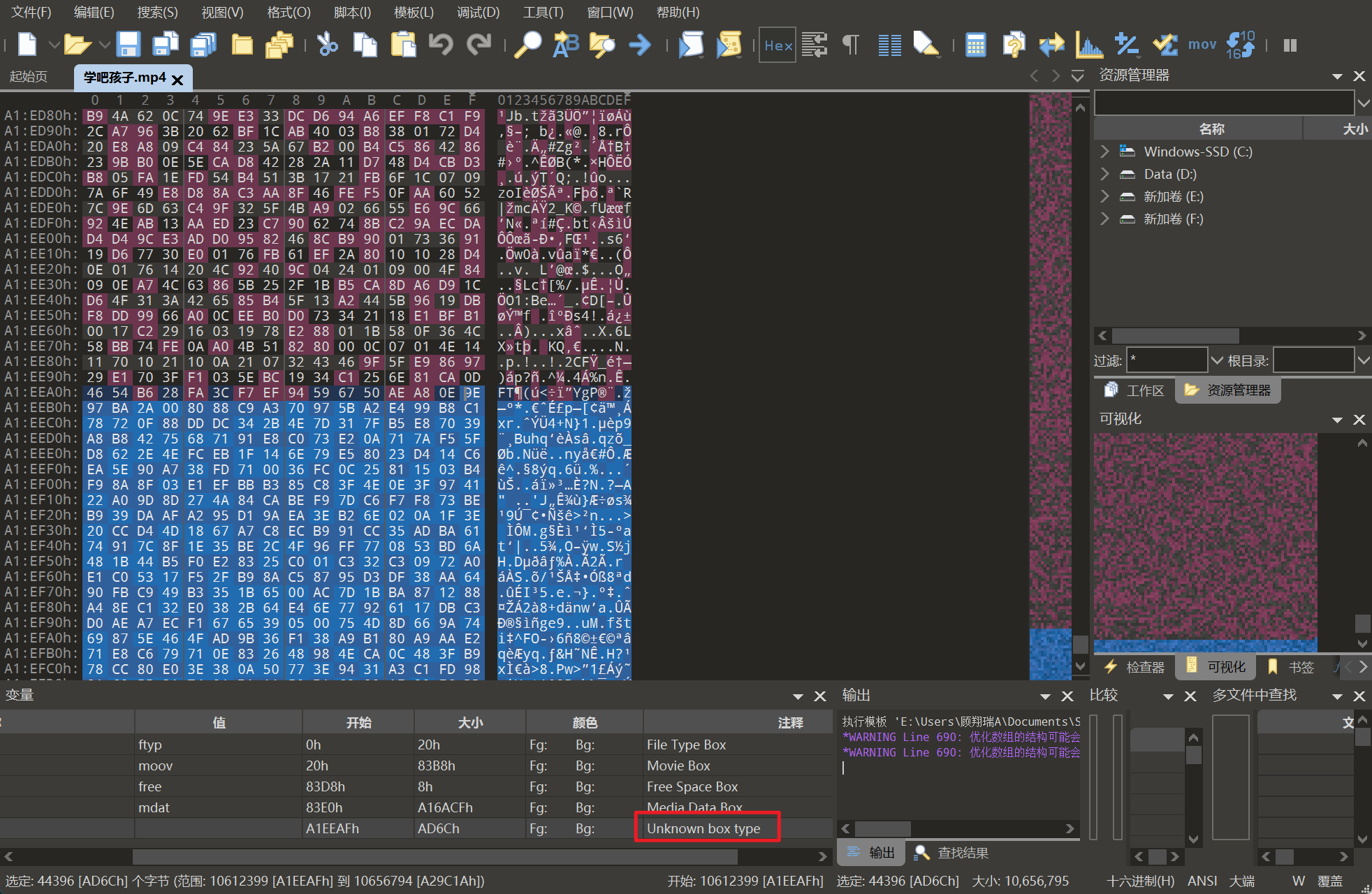
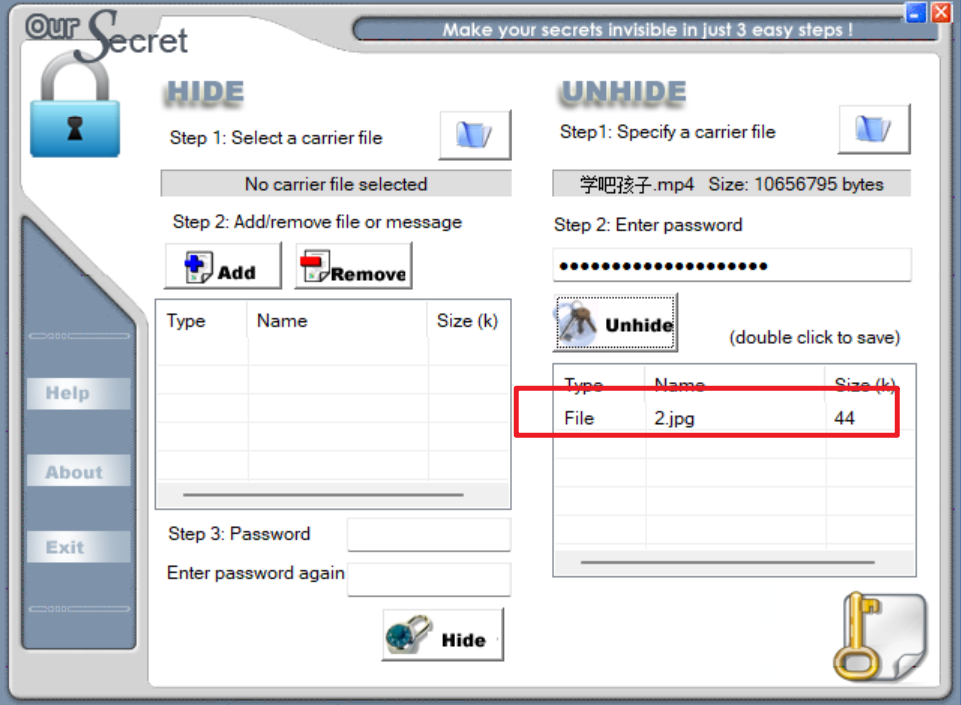
解密出来的图片还是010分析,发现有隐写压缩包,foremost提出来或者直接改后缀,打开发现有加密,观察实际为伪加密(看不出来可以用passware kit或者用随波逐流)
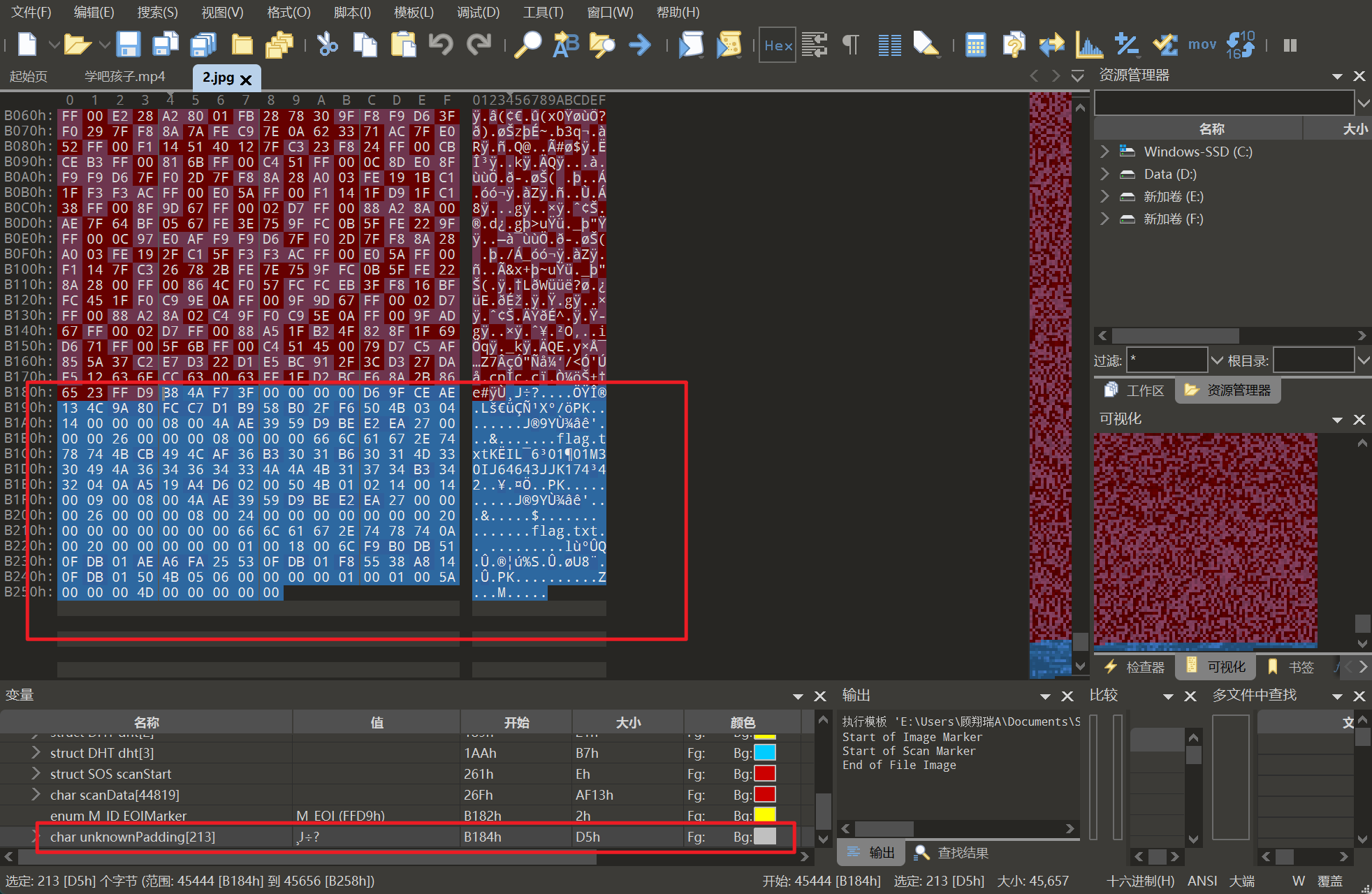
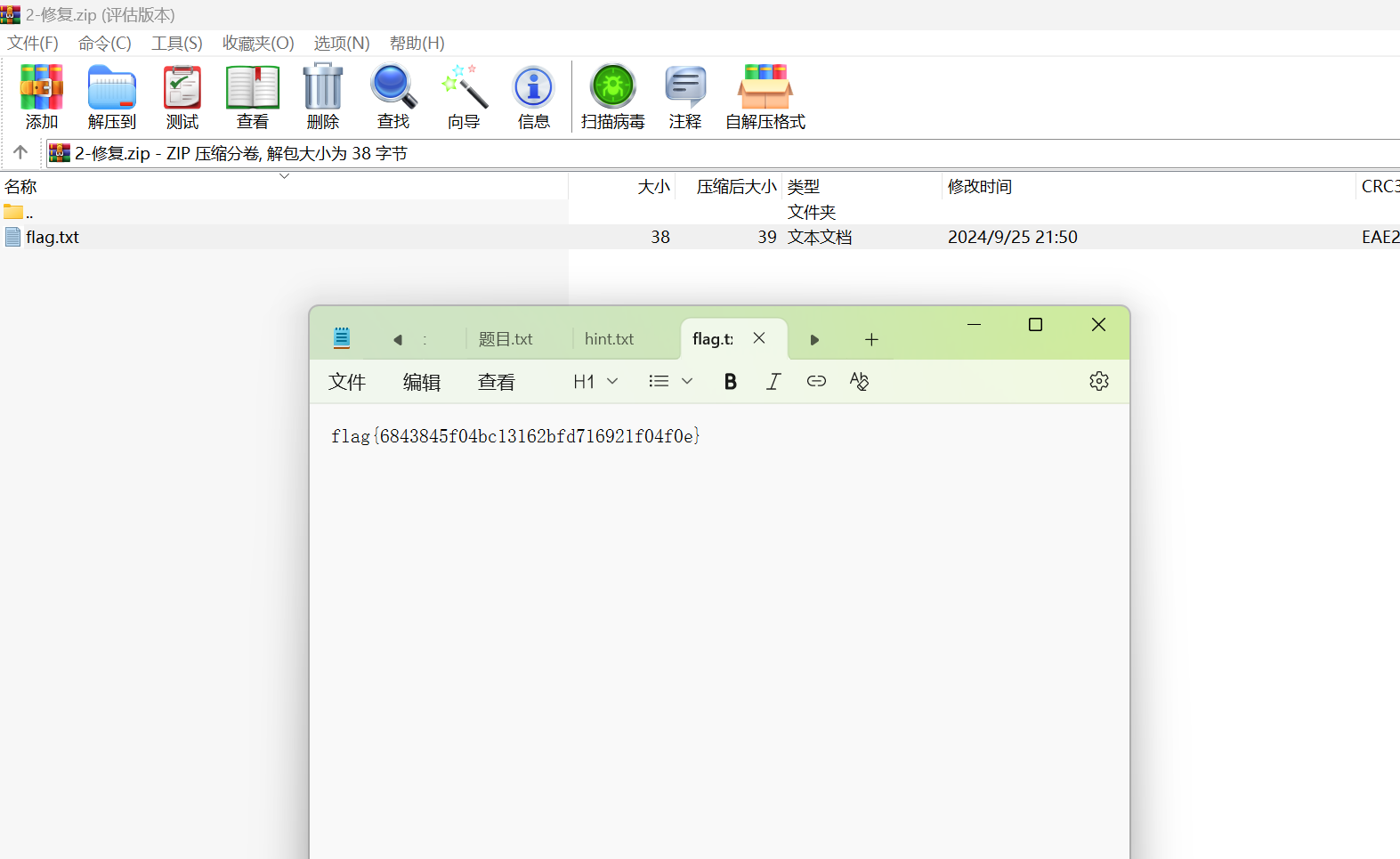
修复后打开即可
1-4 传奇特工
附件解压后一路点到最后,可以在boss那获取一个加密的flag
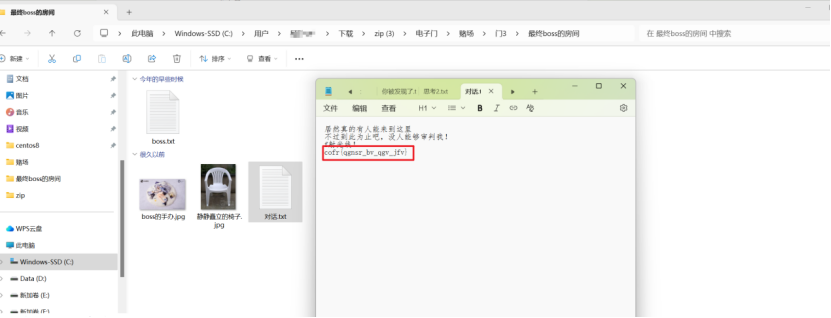
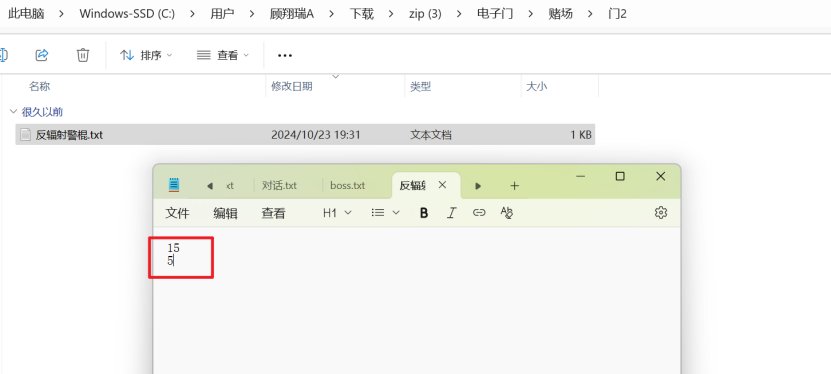
根据说的f射光线,联想到仿射密码,在另一个目录中的反辐射电棍可以得到两个数字,刚好对应仿射的参数,(谐音仿射)解密得到flag(谐音梗扣钱)
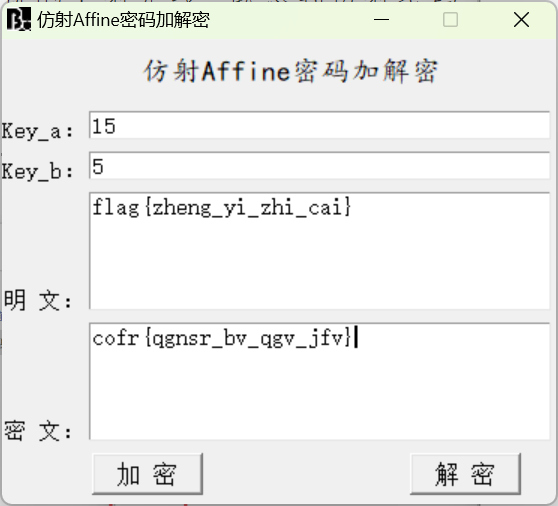
1-5 无限解
这题我得先说,出题用冷门网站工具的我个人是不太赞成的,由于工具问题本本题0解,笔者在赛中解到最后一步了被工具限制无法解得flag,这于出题人于选手都不是什么好事儿,揣摩出知识点却无法解出flag,很难受()
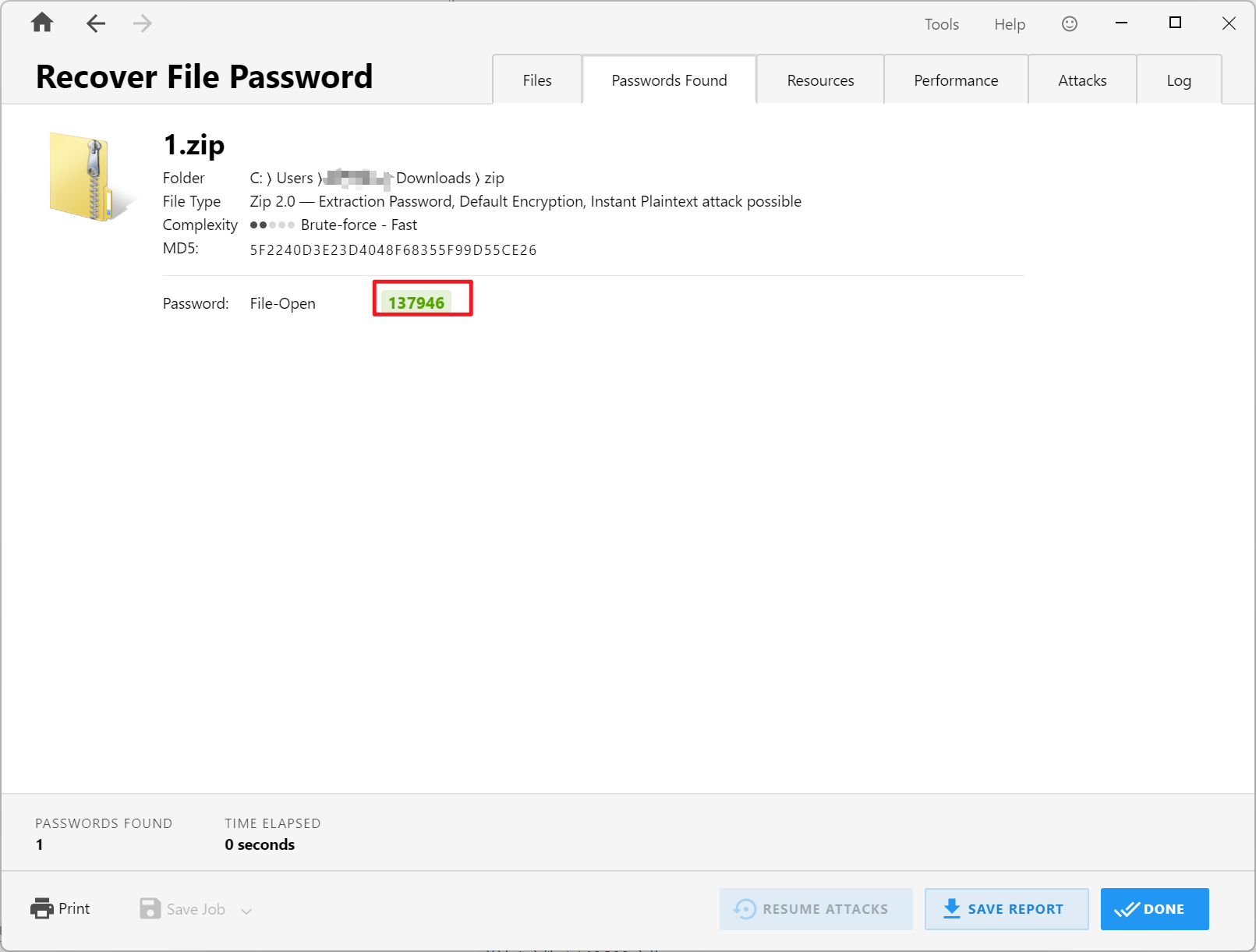
得到的附件是一个压缩包,备注里写的十六进制转出来是nixuyaonaozi,但不是本压缩包的密码,passware kit跑字典得到密码
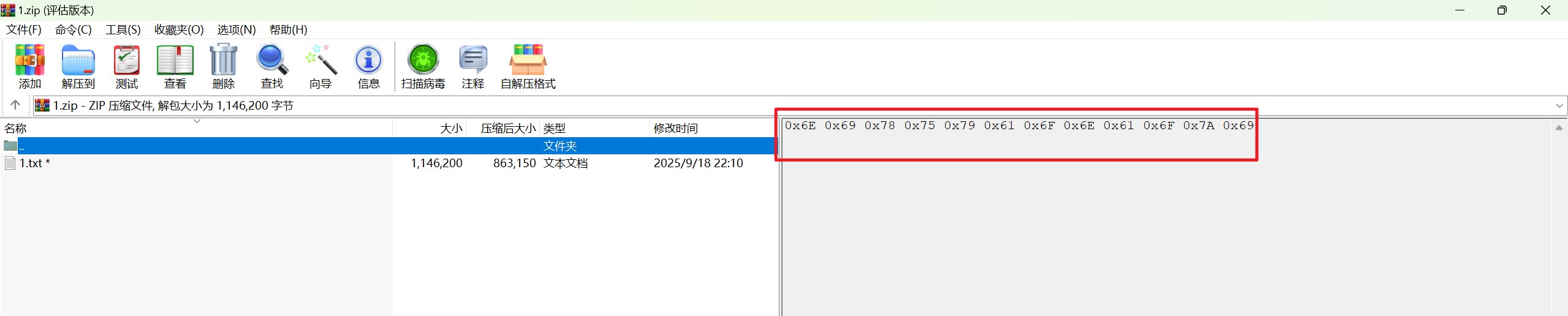
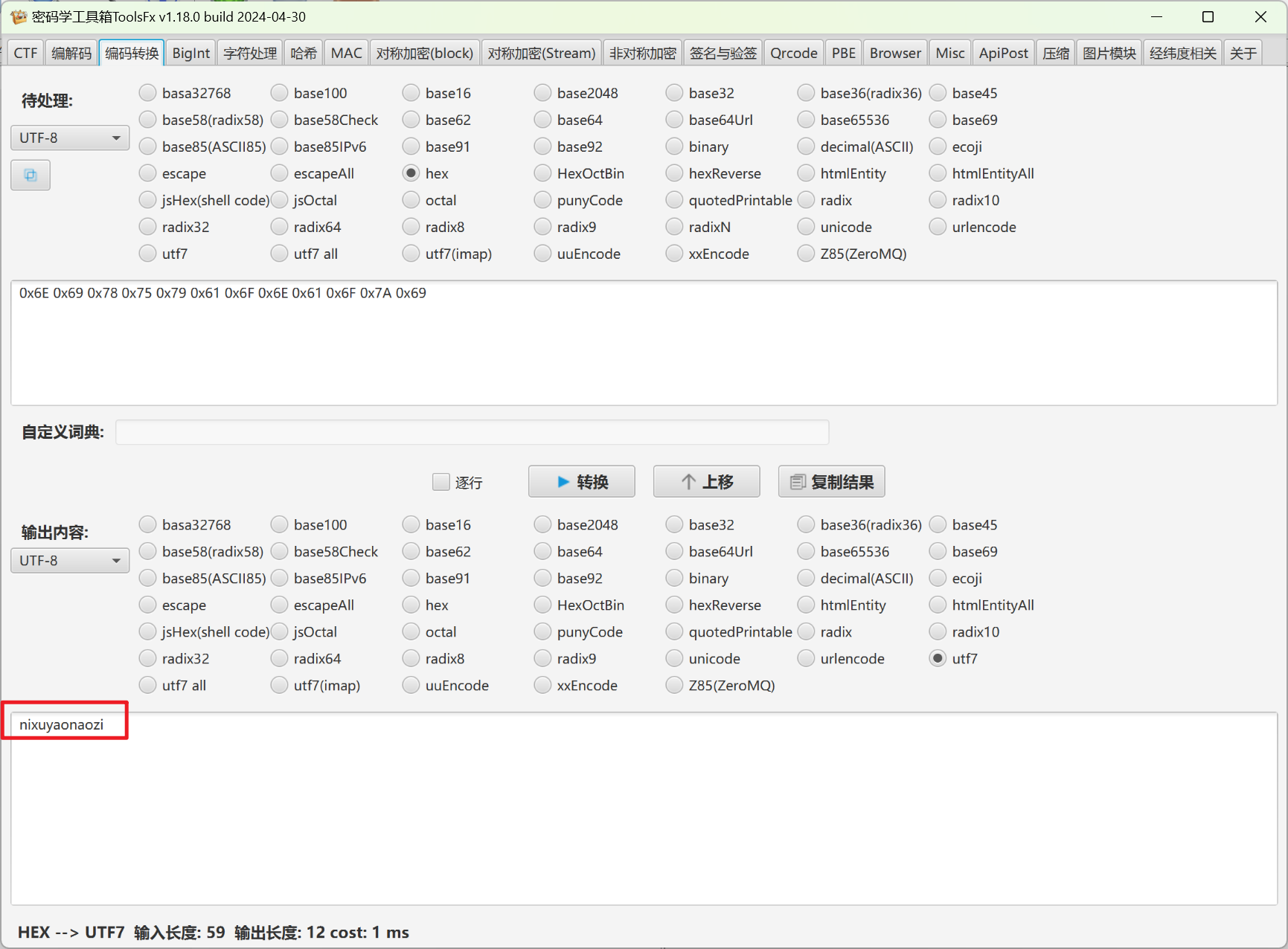
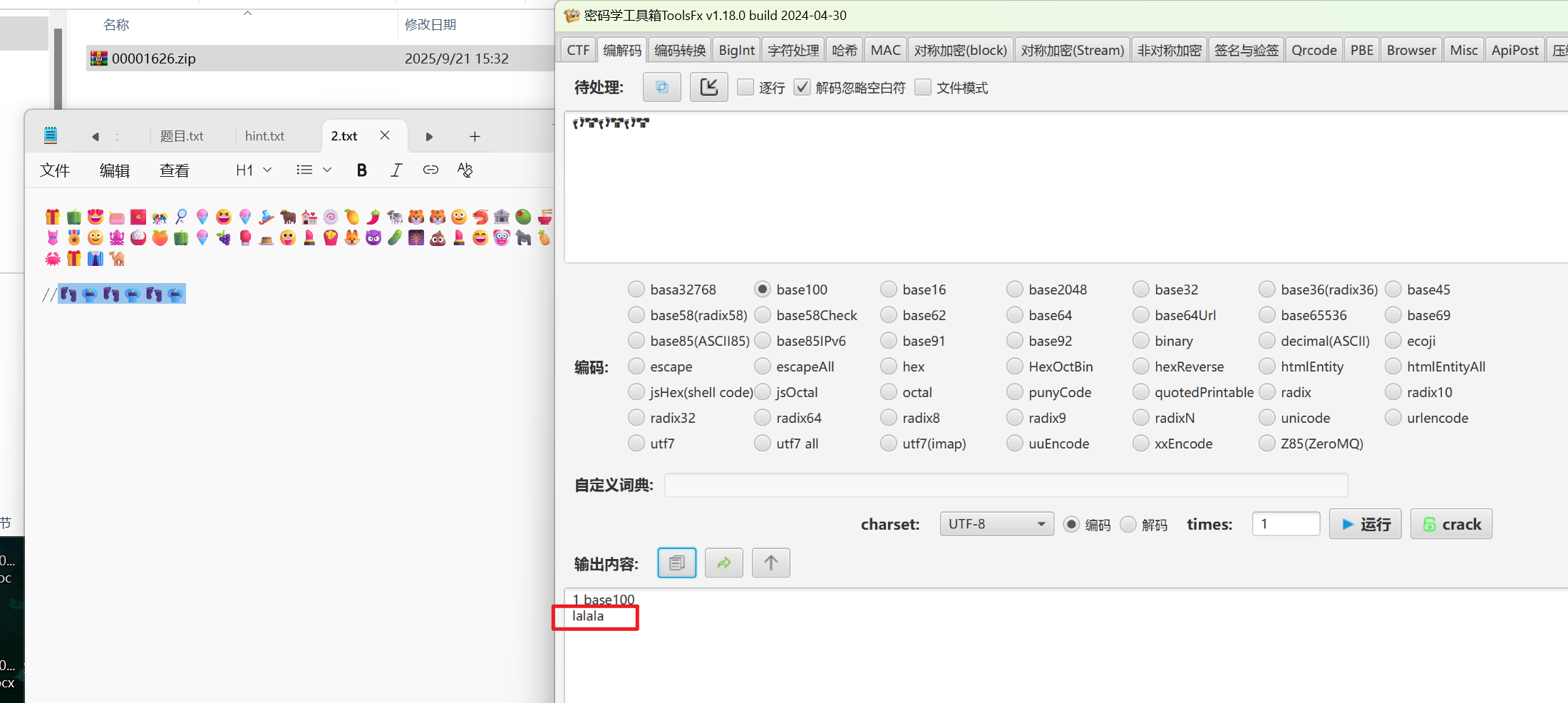
得到里面的1.txt是base64编码,cyberchef解码后可以用detect file type发现是doc文档,另存后打开,需要密码,输入刚才压缩包里的备注,成功打开

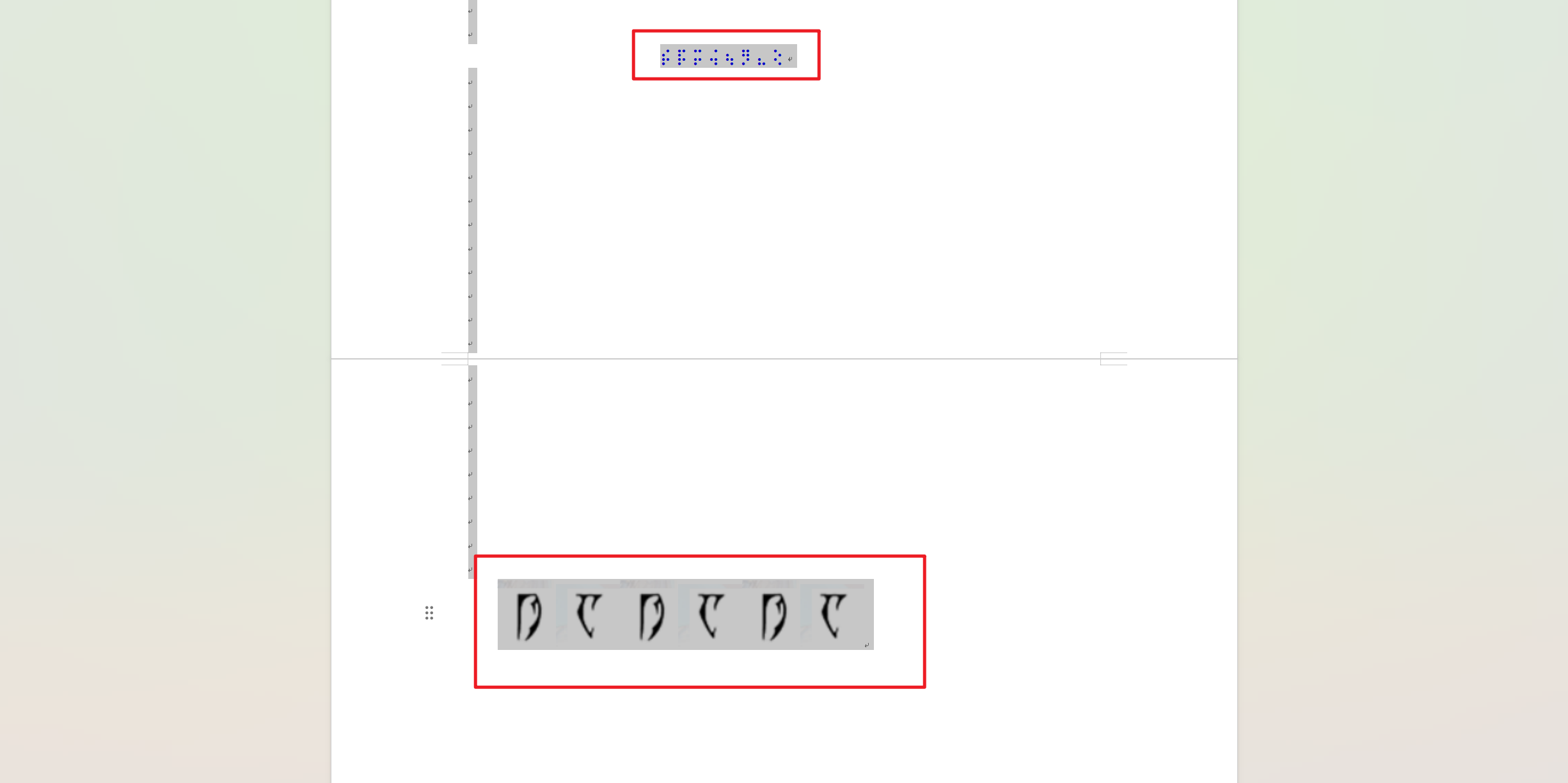
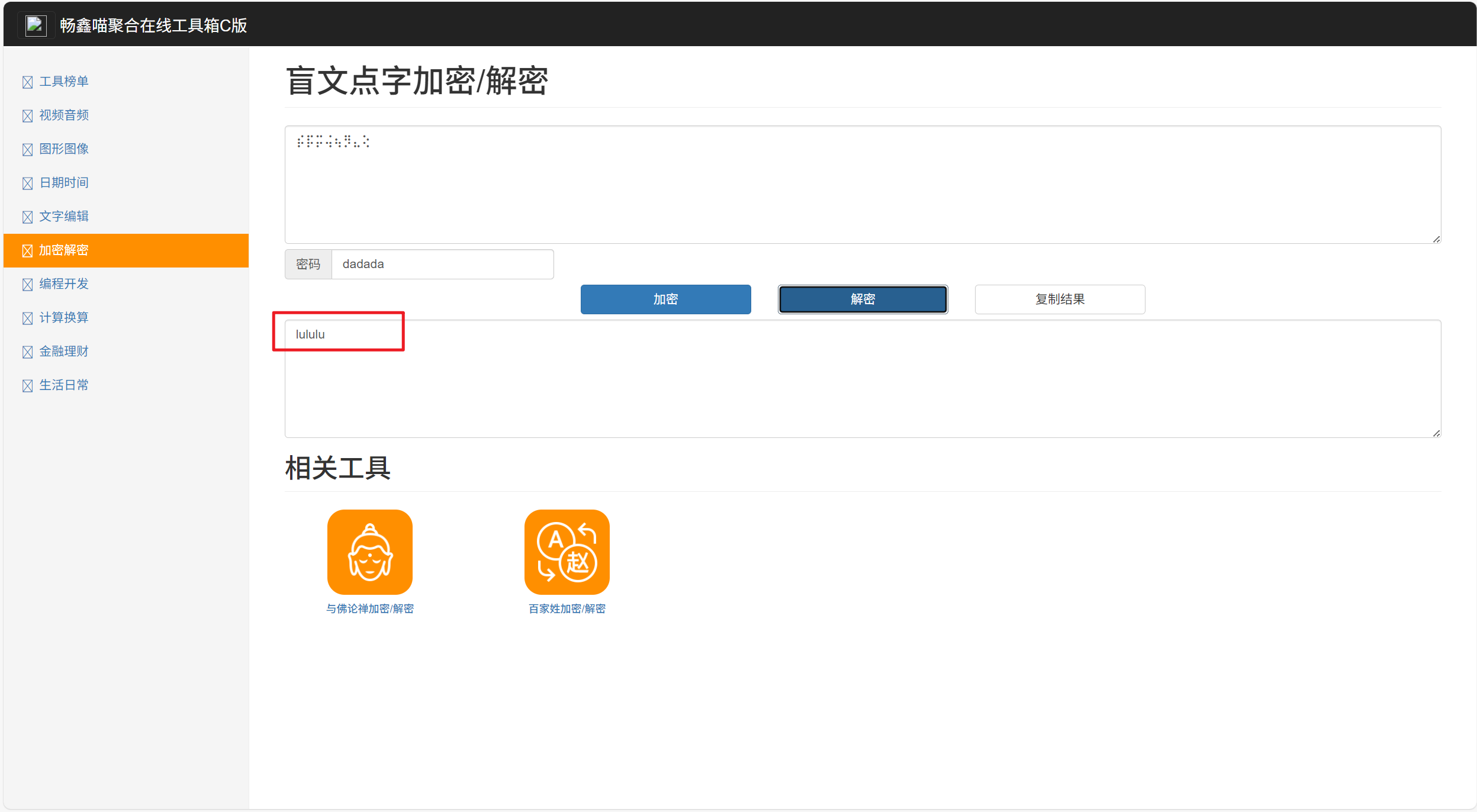
打开后有一个图片,另存出来备用,全选可以看到透明的字符,换颜色后可以发现一个类似盲文的符号,但是是2x4的格式,不是常规的布莱叶盲文(2x3),搜索可得是盲文带key加密的,而下方的图片是狄拉克符号,换出来是dadada,作为key解密出一个新的key lululu

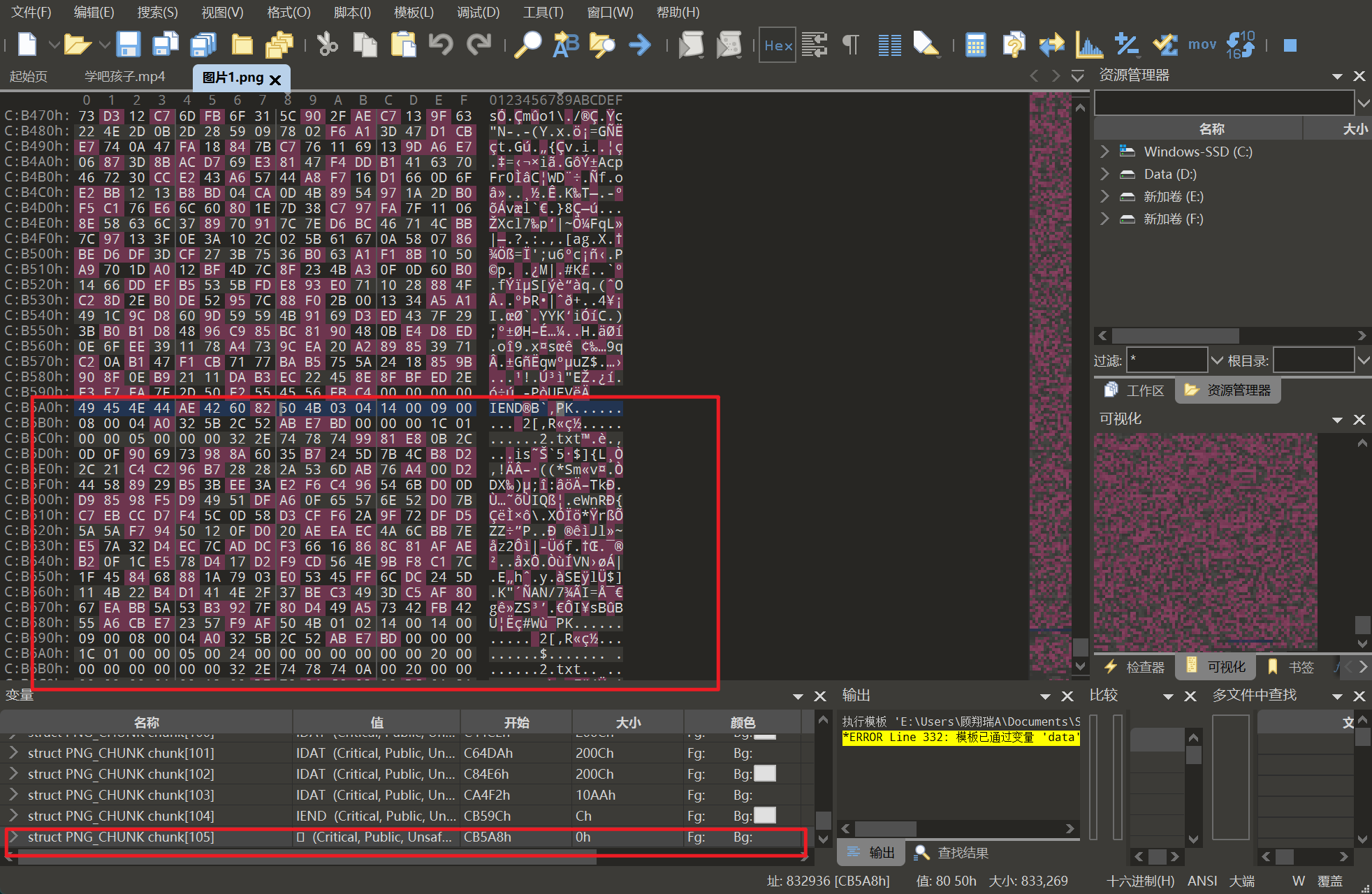
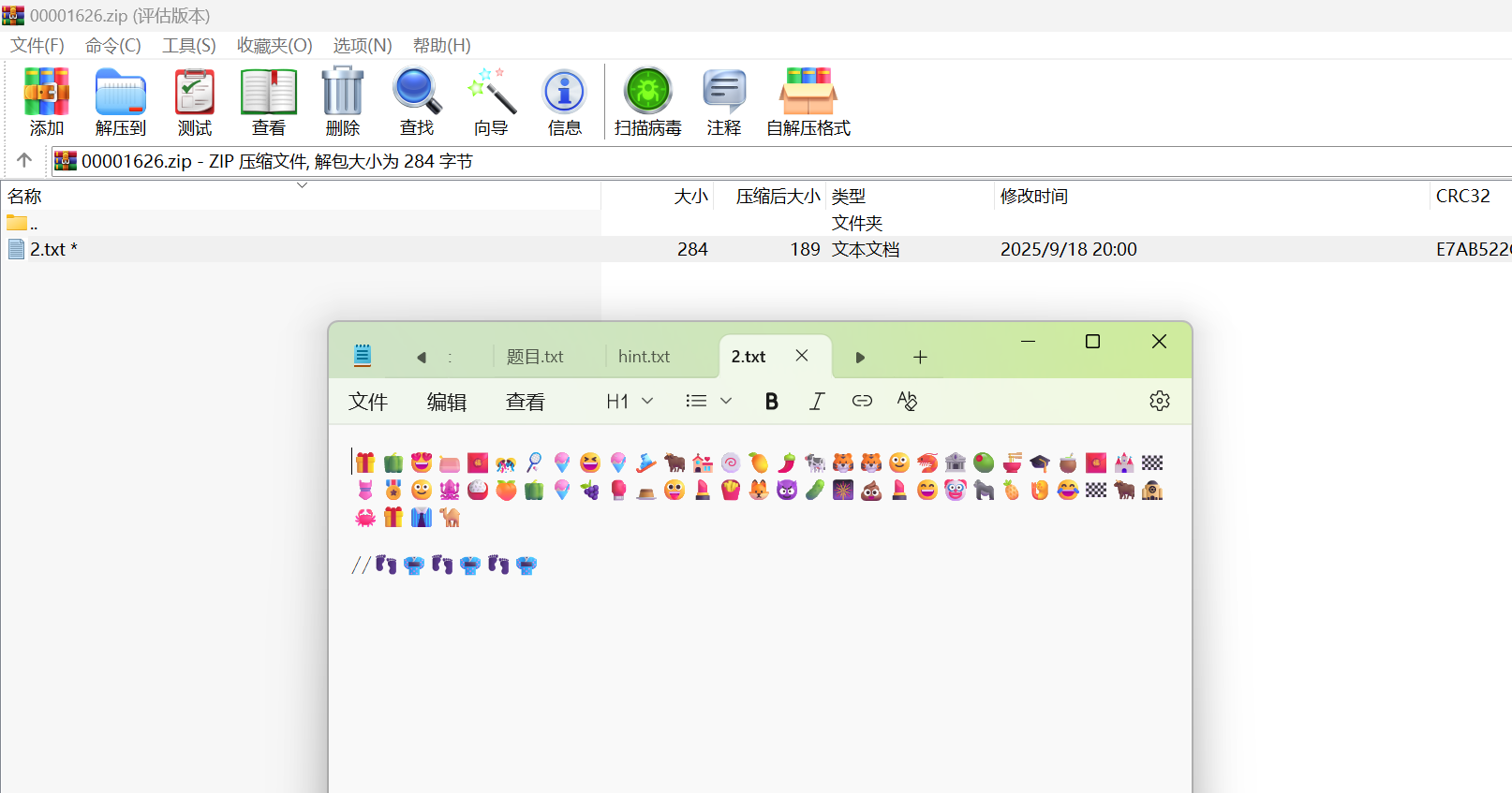
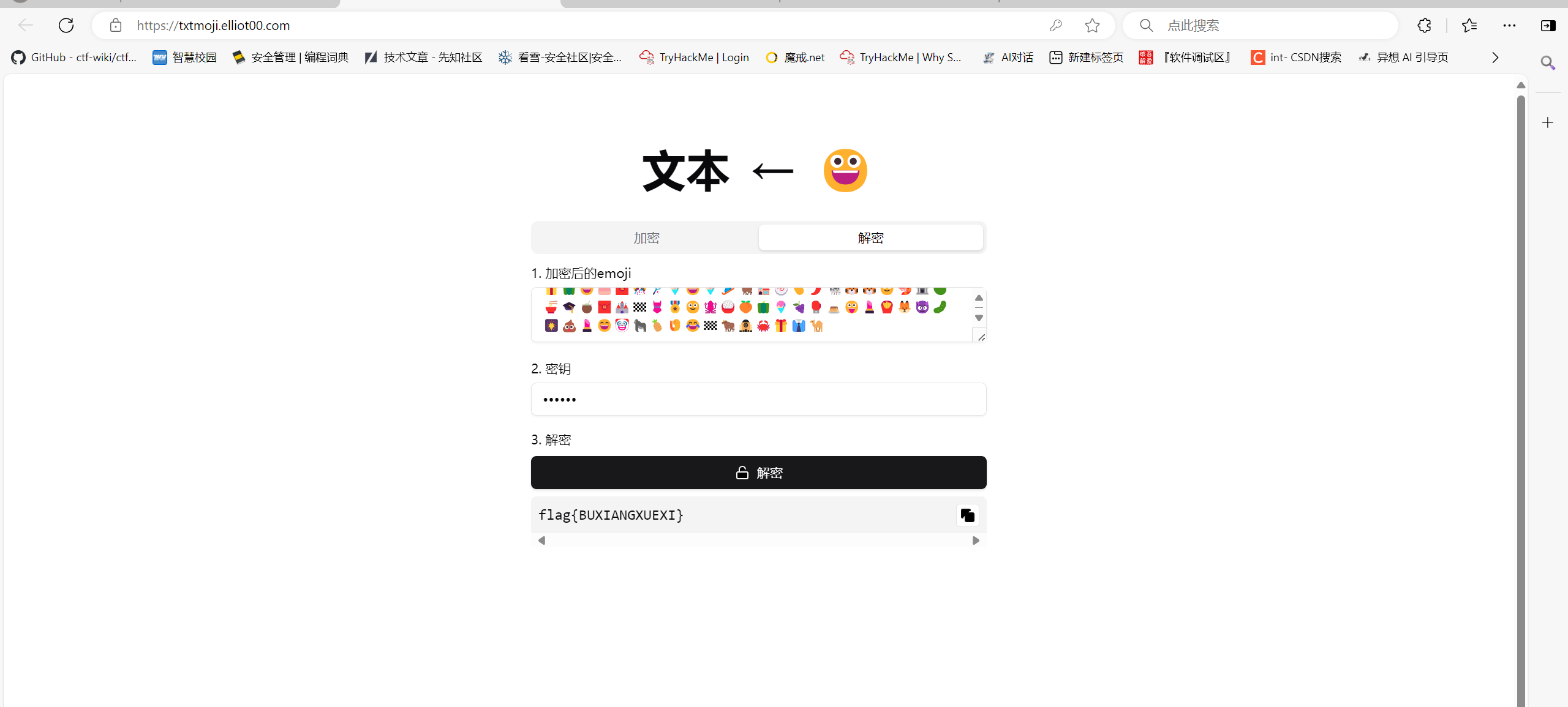
研究图片可以发现也是尾部带压缩包,foremost分出来用刚才的key解压,是emoji符号,下面用双斜线隔开的是base100编码的key,自然联想到emoji-aes加密,但是常规的无法解,需要特定的来解,解完就是flag。
https://txtmoji.elliot00.com/#google_vignette
1-6 lookme
拿到附件,其实没用到宏文件的东西也能做题,笔者在假期期间给家人的电脑查问题时发现了宏病毒,出于安全问题禁用全局宏操作了,从文件的属性中可以看到有备注信息,疑似转摩斯的规则以及用户名
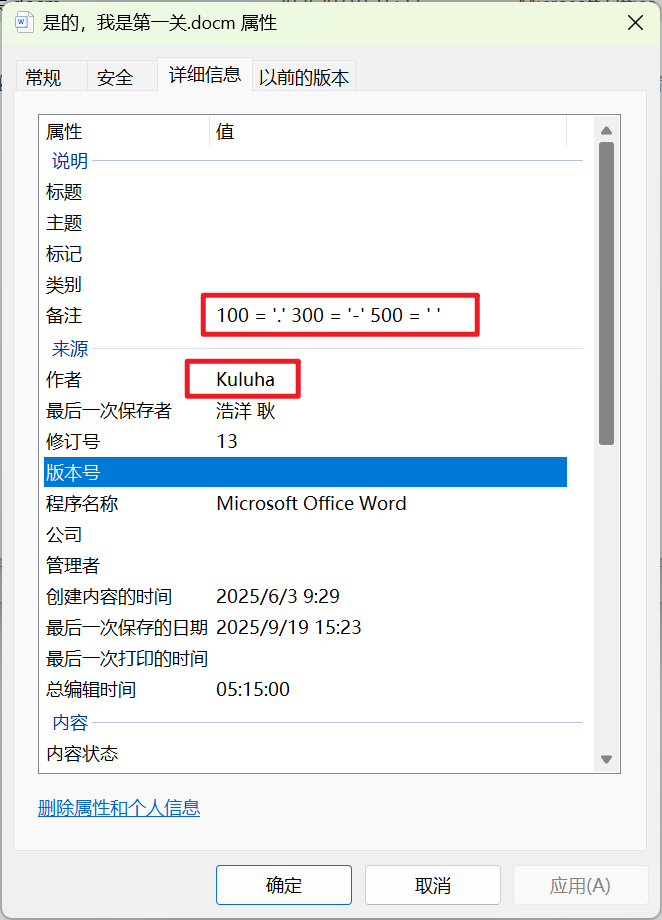
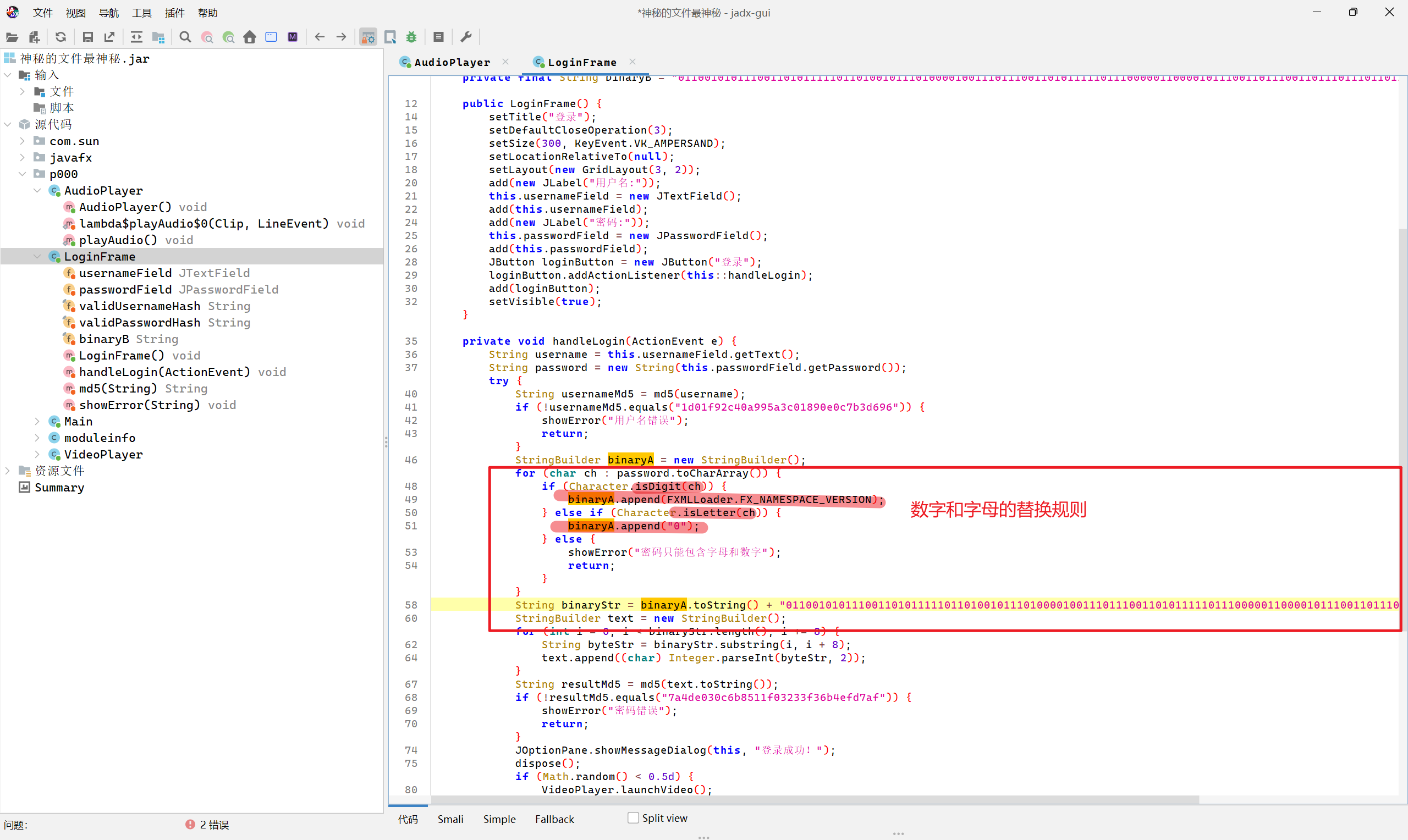
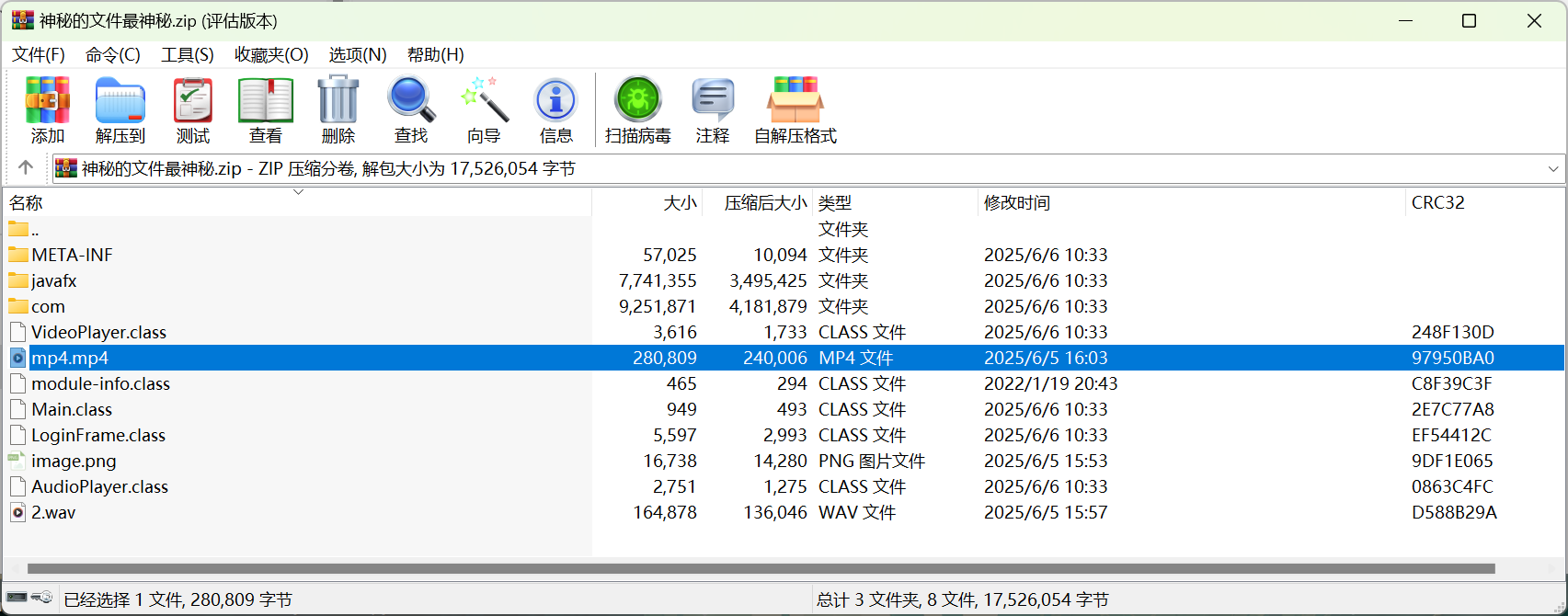
文件中除了最后的gif都没有用了,看到神秘文件,直接加上zip后缀也能用winrar打开,看到meta—info就能猜到是Java写的程序了,不是jar包就是apk,可以看到附带的音视频文件,先解压出来,将压缩包放入jadx反编译看看逻辑,是一个登录器的逻辑,那刚才的用户名就有用了
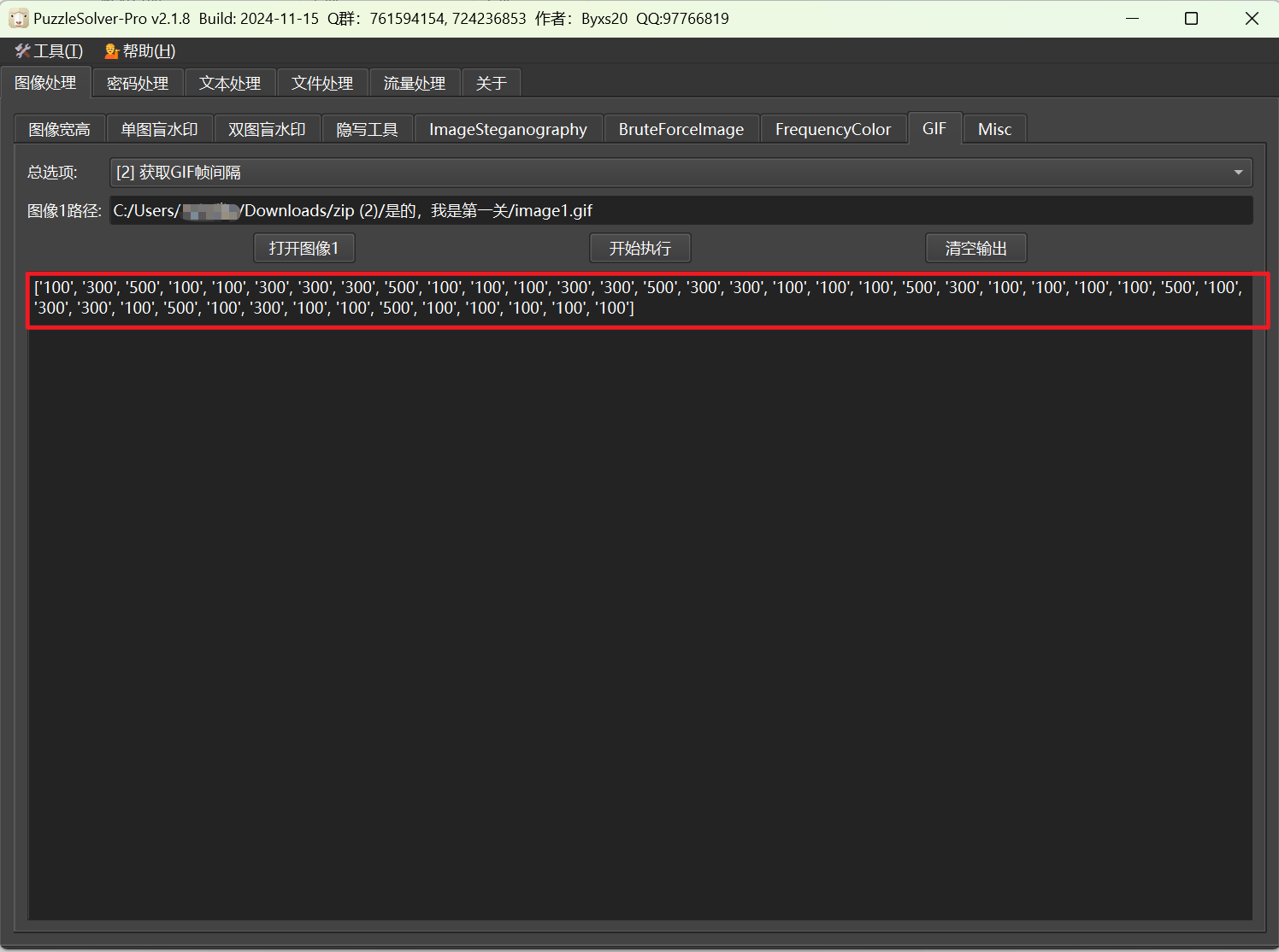
先来研究gif,帧数明显有异常,用puzzlesolver提取帧间隔,可以发现和刚才的规则出现的是有关的,转一下得到一个字符串
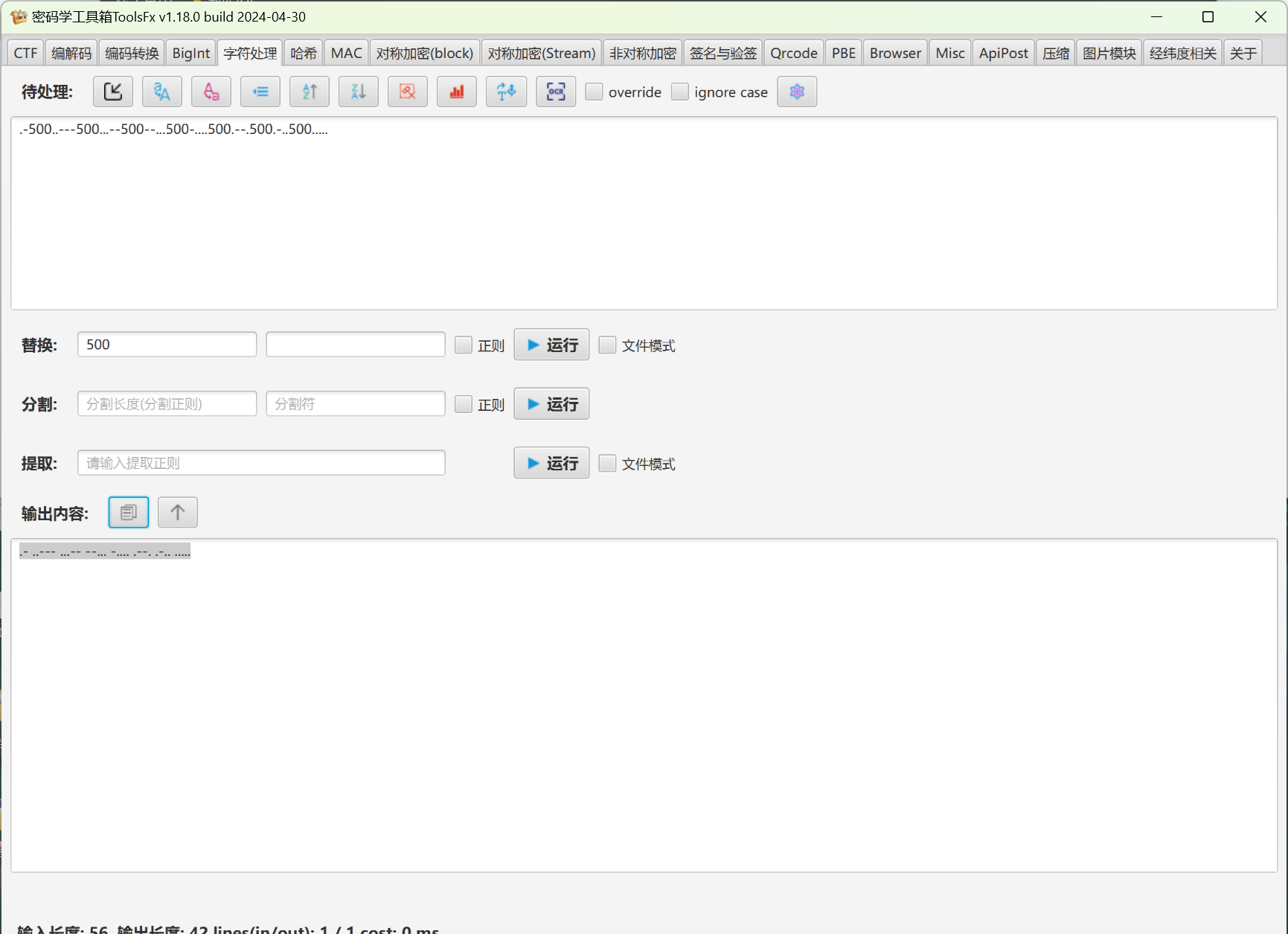
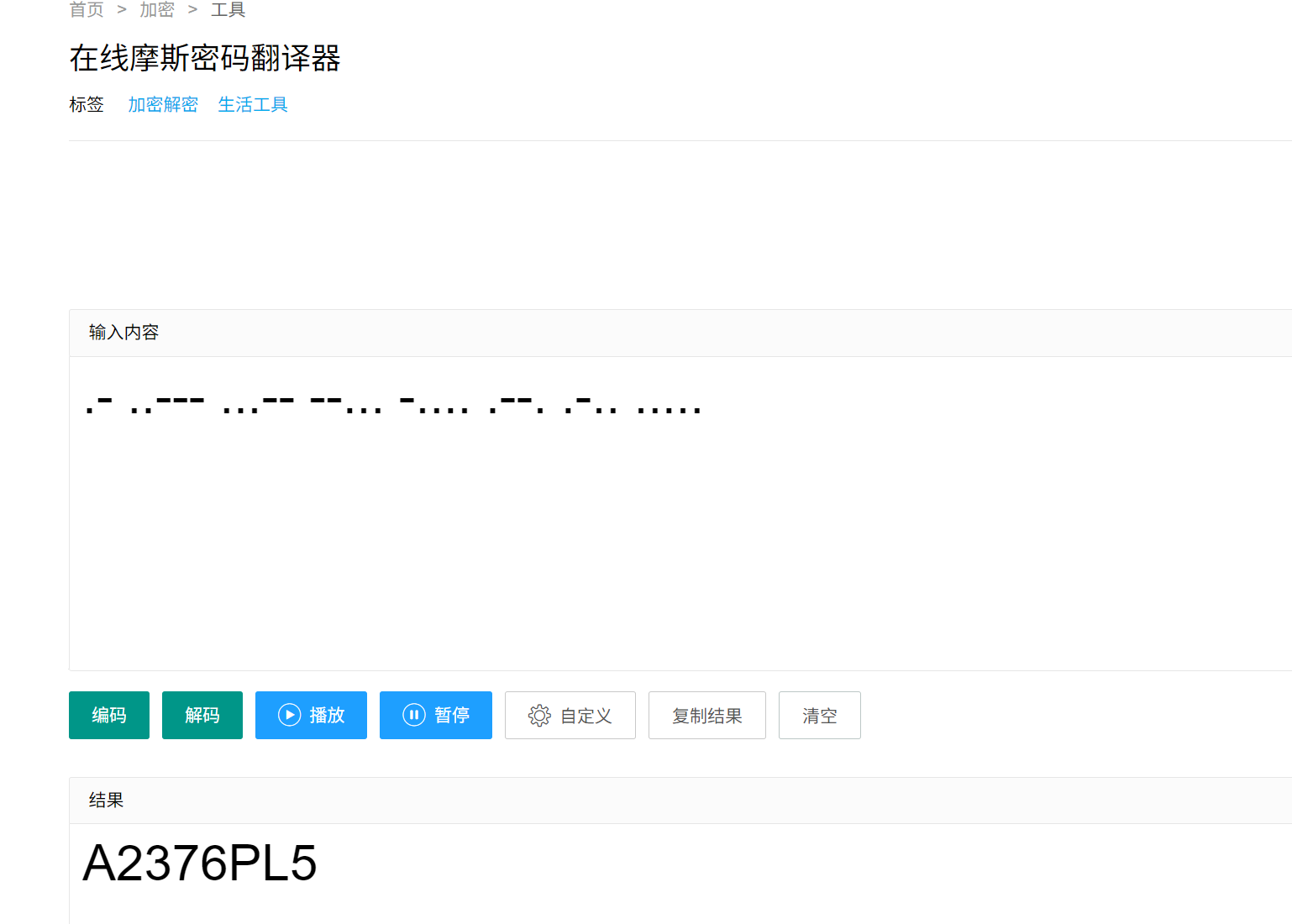
反过来检查登录逻辑,是对正确的密码按规则转换后(字母转0数字转1)加上一串二进制数,把摩斯电码转的字符串按规则转后加上,二进制转字符得到一个密码
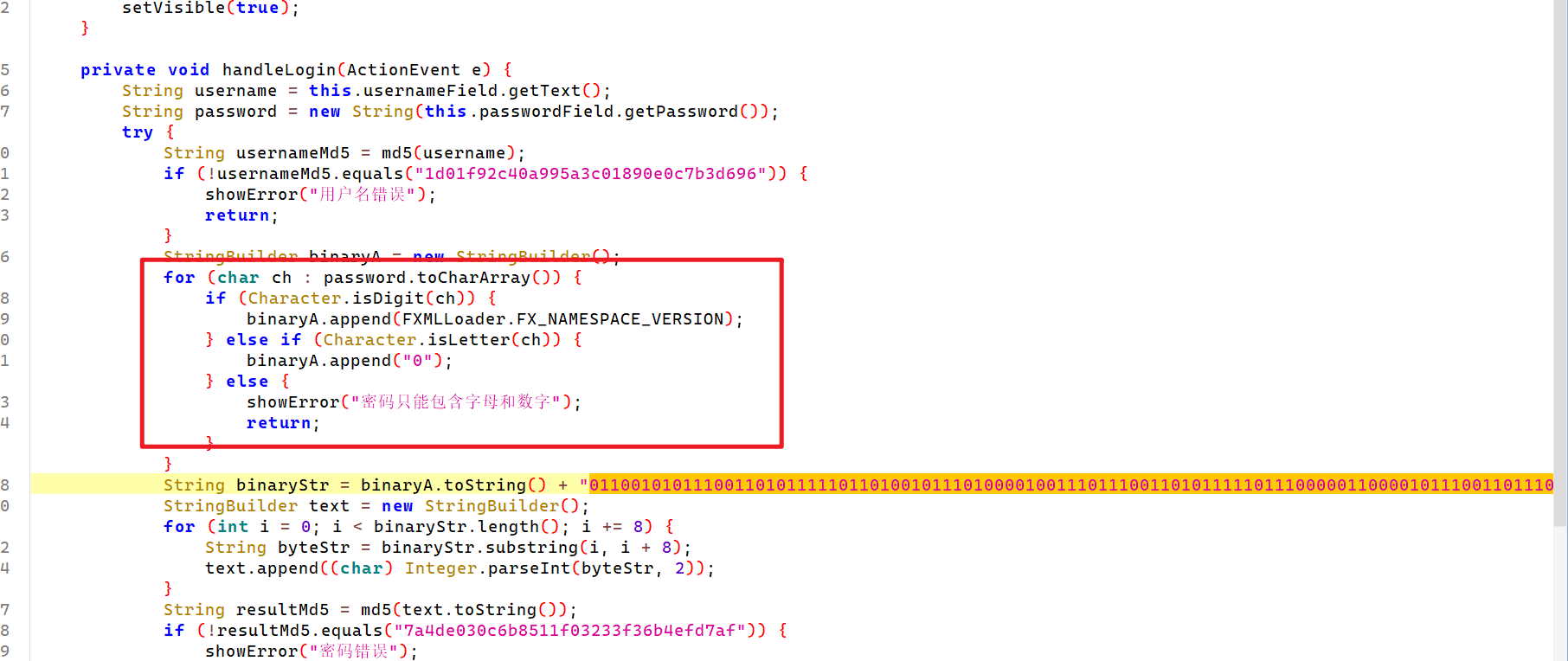
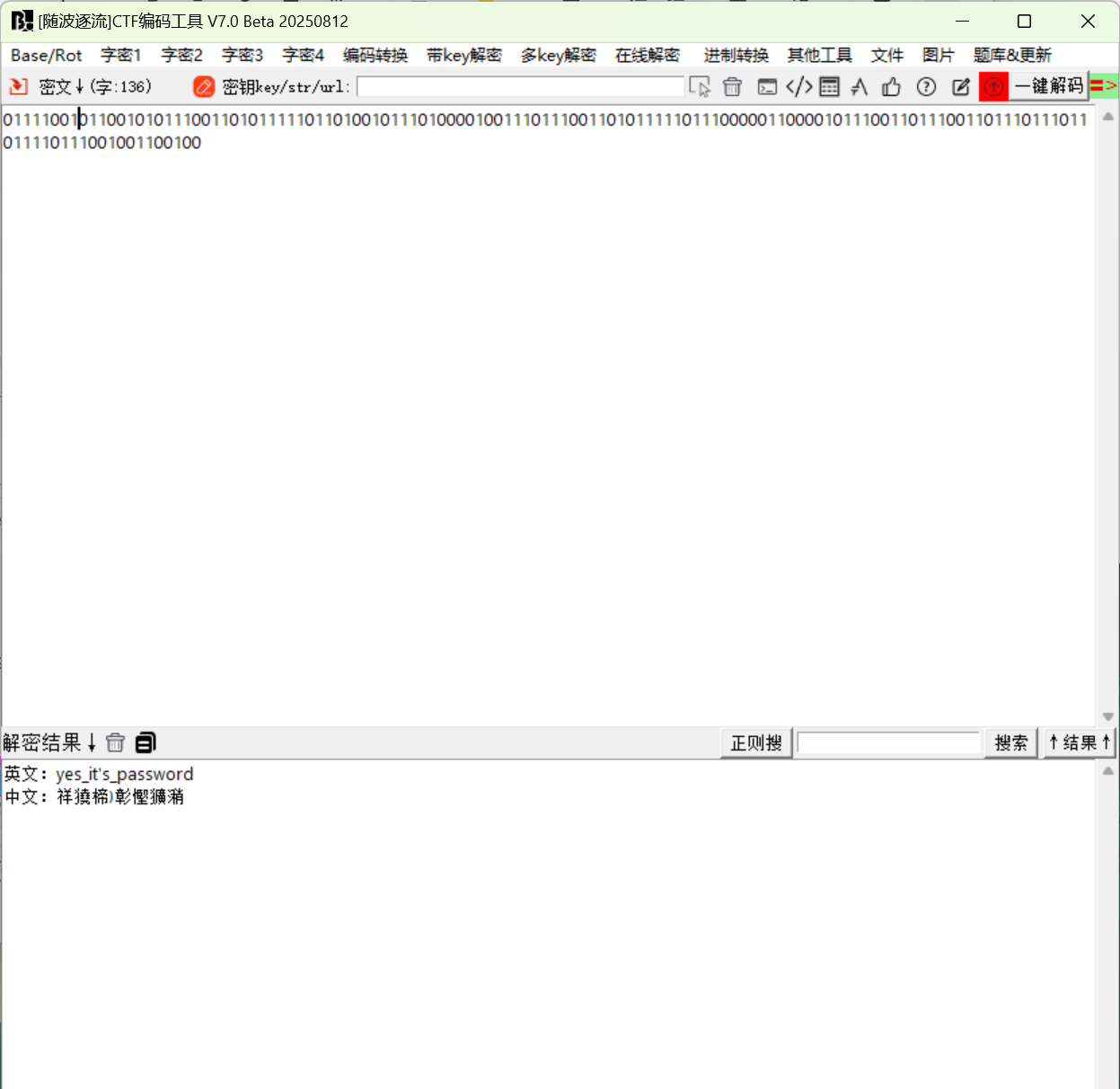
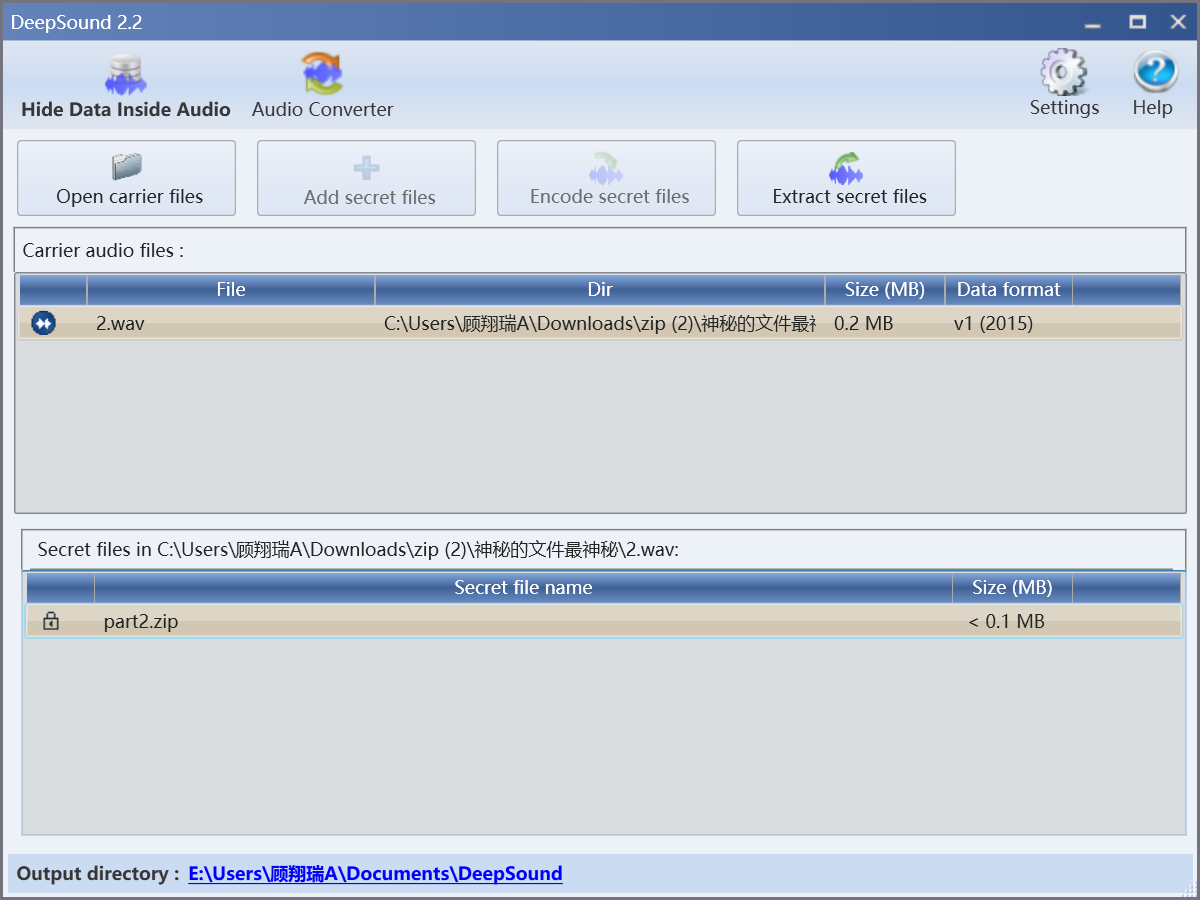
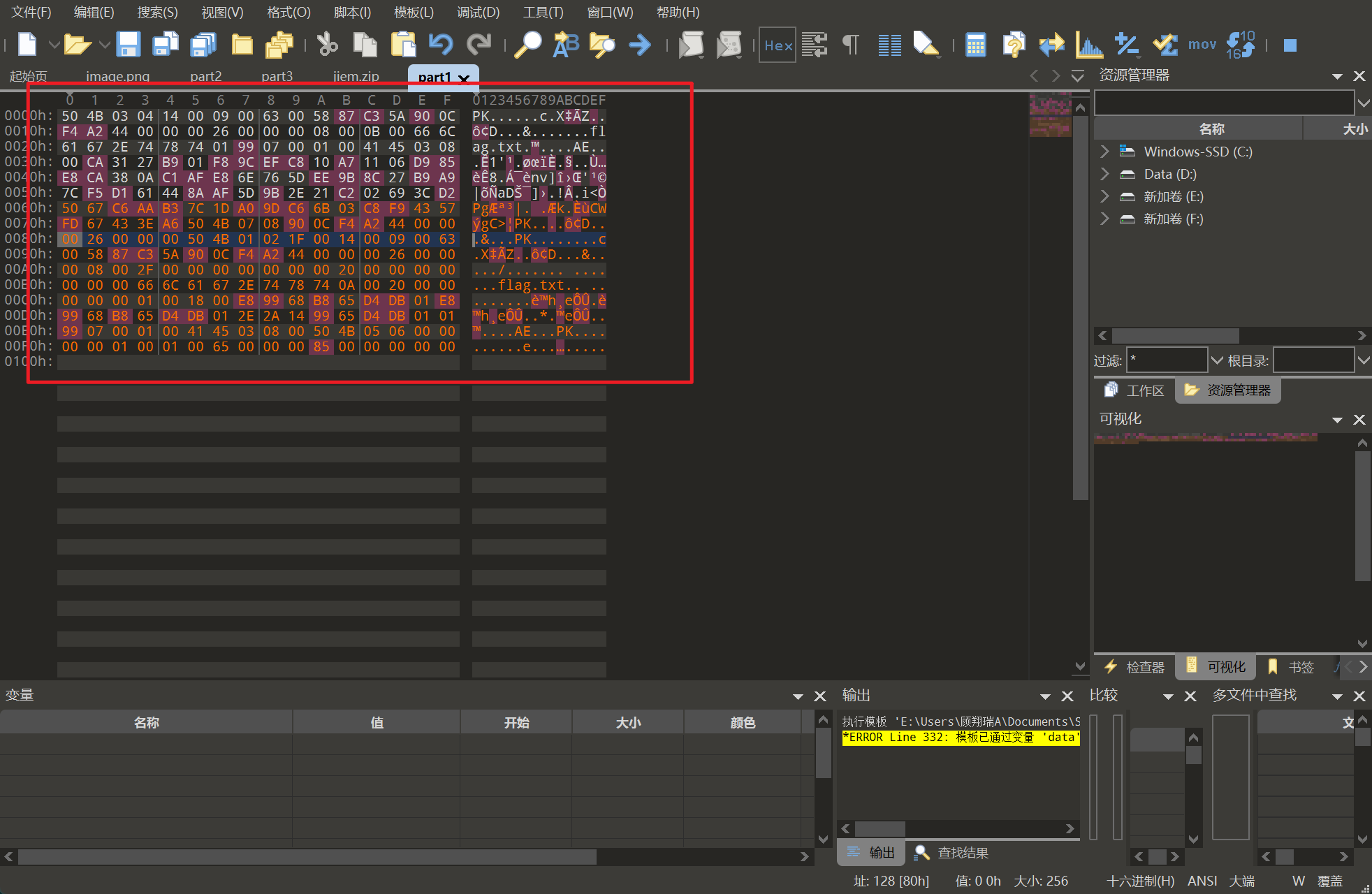
现在检查几个媒体文件,分别是文件尾部隐写,deepsound隐写和oursecret隐写藏起来的三部分zip,提取拼接后用刚才拿到的密码解压即可获得flag。
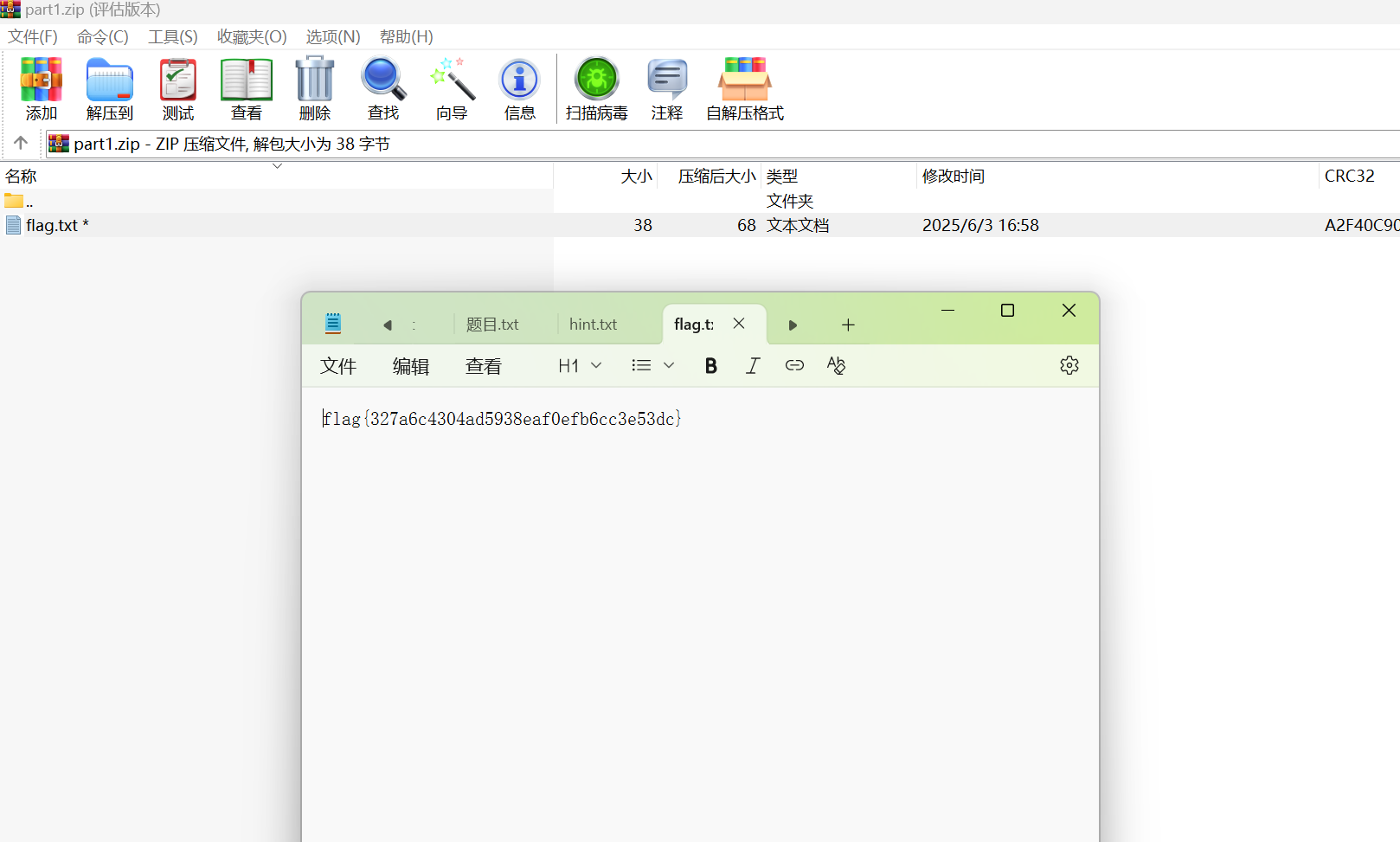
1-7 blackbox
用diskgenius挂载虚拟磁盘,在usr/fdr下找到飞行日志
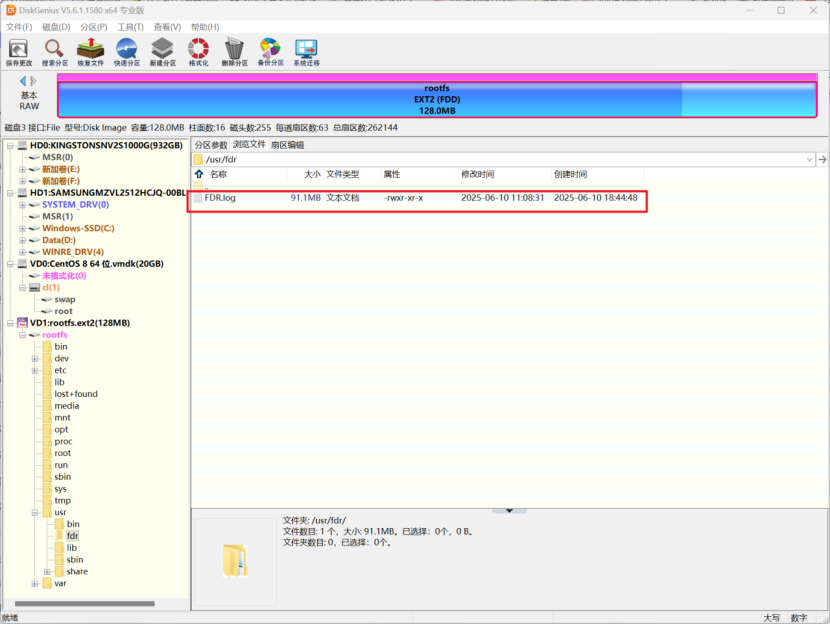
第一条记录就是起飞地点
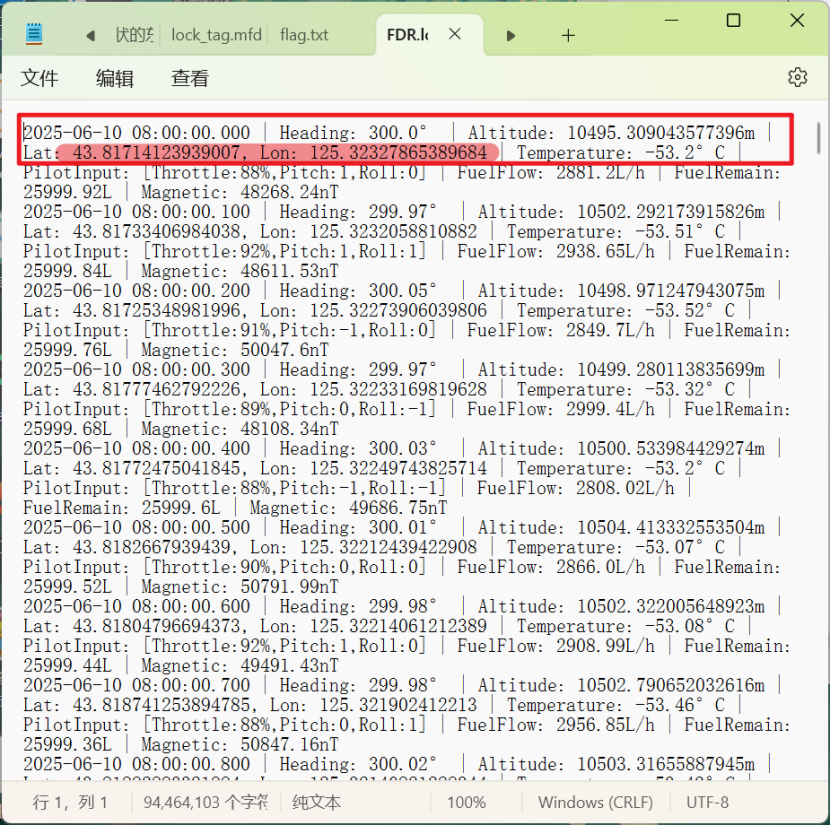
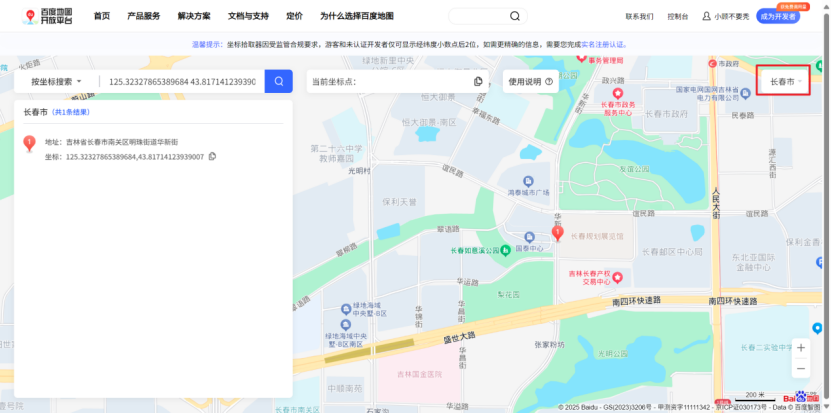
但是要注意算md5的是长春,不带市,flag{2018c3e9567630879ae89d0d71d0d9f2}
关于降落加油,只需要观察油量变化多到少再变多的那个时间节点即可,flag{6b2a2d2cc39bd97799e3793677f69596}
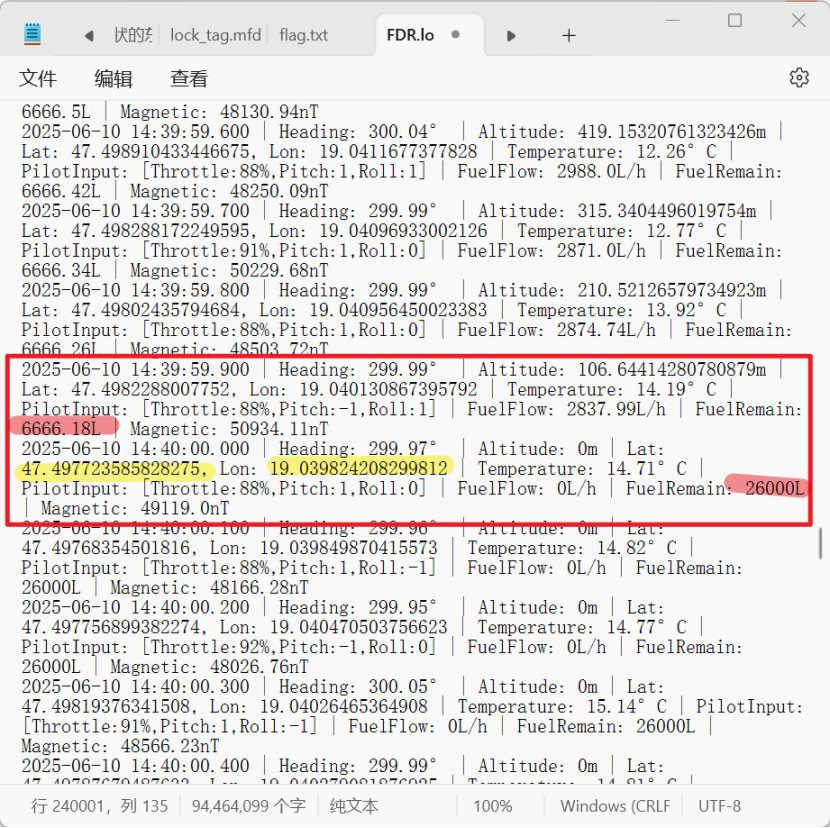
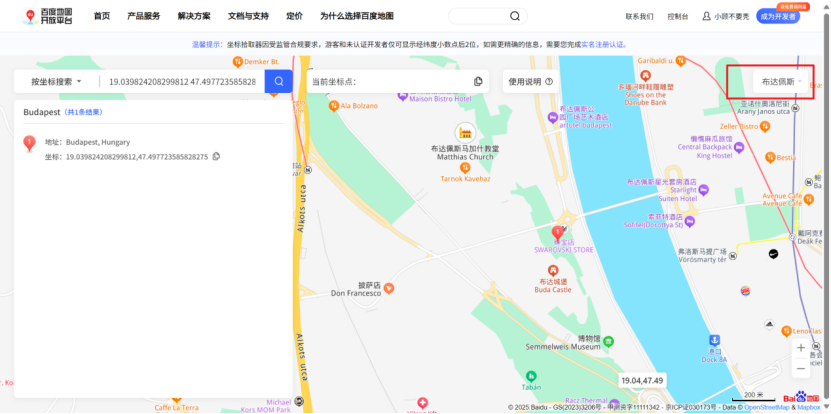
坠毁国家的话,定位到记录中最后一条有效数据即可,可以定位到是乌克兰的位置
flag{6a9bbb8abdb2273ec078bcbc609c706d}
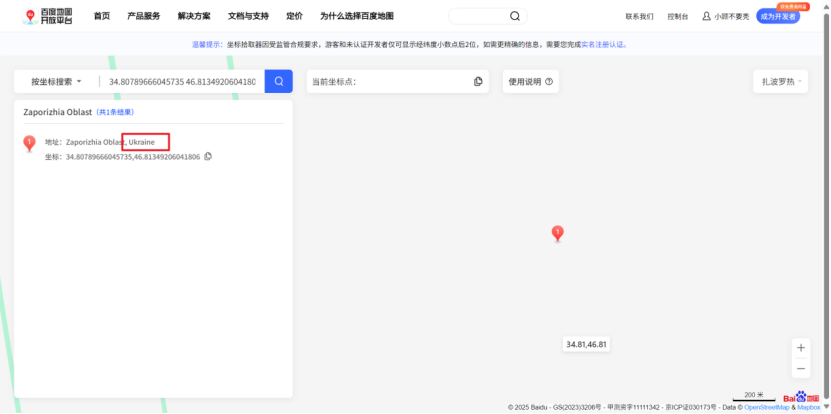
最后一问纯运气,在发现数据出现混乱的情况下,后面还记录了很多混乱信息,就怀疑是电磁干扰了,尝试汉字后用了emp碰对了,正解在后续记录中可以看到emp的记录。
1-8 safeline
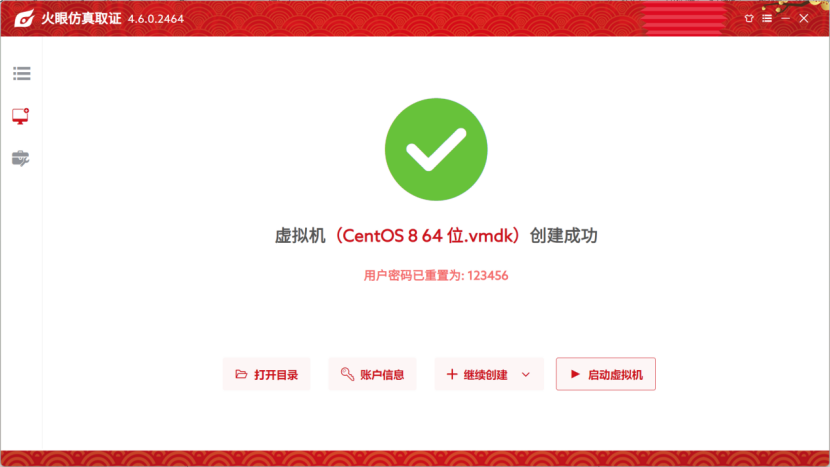
用火眼仿真打开虚拟机,自动修改密码为123456,登录后用su root转root权限,调用history查看历史命令,可以看到23
问的账号xing和密码PC12138.分别转md5提交即可,其余的题,在镜像中把docker启动起来访问雷池waf就能翻出来(懒得写了)
crypto
2-1 dp
大数分解,还是拓展欧几里得,拷打ai得到解密代码
import gmpy2
from Crypto.Util.number import long_to_bytes
n = 12578968303587016591696984144842278531085608644538722445643594895878848074658891359016709469376986447260021300512554570185561754124577042491369062499416380944980856240249651939664960477806414745383319063922229506503418934060463301255807572575066493525002771223282870820853997385483367093867370907374230027018661420381885838640791365367525719331329480988200771096028961511002959549151007128921485411171052051281875882309061806043145083896709695631992529395234023701567365600098543960258861501185646814956935771499932528671860486342164379937160281946324308107464022324435492836422157253681929837382302100089689185903543
e = 65537
c = 10906276715864356369761632637439758066716683780648137744126072657841898843712659394769687552047527567375001824569527779129458322752449881841845168035235173523774510512214330455988134166183657805538570704572428007110041354744982723114044600444986674273293892286168522231581555310259369154013437237933251555478213229593686630613376949296400970077781344319026078564004777742555035765704636347921539584221643767240411400125700438431682388088093313002328072974808202517706548936697848298656102522908974091806258018418608179915189558303275877055698315265720890388838334992008457424886601286341487348129350032040480978103932
dp = 18201764572787500738319290000500334669930850070624591899596635450845296515293662436246999549668853246028284395784534709802829720655629032200503991304922253762728508125091402709220239941438549515725907441334659071104341643800949670955272406512622232954850869527016746828399325512302620436300591710797354204801
Step 1: Compute t = e * dp - 1
t = e * dp - 1
Step 2: Compute y = 2^t mod n
y = pow(2, t, n)
Step 3: Compute p = gcd(y - 1, n)
p = gmpy2.gcd(y - 1, n)
Step 4: Compute q = n / p
q = n // p
Step 5: Compute phi(n) = (p - 1) * (q - 1)
phi = (p - 1) * (q - 1)
Step 6: Compute d = e^(-1) mod phi(n)
d = gmpy2.invert(e, phi)
Step 7: Decrypt m = c^d mod n
m = pow(c, d, n)
Convert to bytes
flag = long_to_bytes(m)
print(flag.decode())
2-2 LCG
线性迭代器,ai获得代码
from Crypto.Util.number import long_to_bytes
已知数据
s7 = 32291470504423929090613539115141871097090 # 第8次迭代结果
s8 = 6094103004570805782293623413304798708542 # 第9次迭代结果
s9 = 259587097163287690998066063140610337840 # 第10次迭代结果
a = 30922158886696003547511019464837123248227
b = 39805048296461489898496559018969443222861
m = 43121932661075616230371590712923207613847
计算a的模逆元
a_inv = pow(a, -1, m)
从s10回溯到s0(需要10步)
current = s9 # s10
states = [s9]
for _ in range(10): # 回溯10次
current = (current - b) * a_inv % m
states.append(current)
获取初始种子s0
plaintext = states[-1]
正向验证:从s0开始迭代10次
seed = plaintext
for i in range(10):
seed = (a * seed + b) % m
if i == 7: # 第8次迭代
assert seed == s7
elif i == 8: # 第9次迭代
assert seed == s8
elif i == 9: # 第10次迭代
assert seed == s9
print("正向验证通过!")
转换为字节并处理编码问题
flag_bytes = long_to_bytes(plaintext)
尝试不同解码方式
try:
# 尝试UTF-8解码
flag = flag_bytes.decode('utf-8')
print("Flag (UTF-8):", flag)
except UnicodeDecodeError:
try:
# 尝试Latin-1解码(可处理所有字节)
flag = flag_bytes.decode('latin-1')
print("Flag (Latin-1):", flag)
except:
# 如果都失败,打印字节和十六进制
print("解码失败,原始字节:")
print(flag_bytes)
print("十六进制表示:")
print(flag_bytes.hex())
# 检查是否以flag{开头
if flag_bytes.startswith(b'flag{'):
print("检测到flag{开头,尝试部分解码:")
# 尝试解码前7个字节(flag{)和最后字节(})
head = flag_bytes[:5].decode('utf-8') # "flag{"
tail = flag_bytes[-1:].decode('utf-8') # "}"
print(f"部分结果: {head}...{tail}")
2-5 假如给我三天光明
盲文加曲路密码,主要是最后要加md5提交
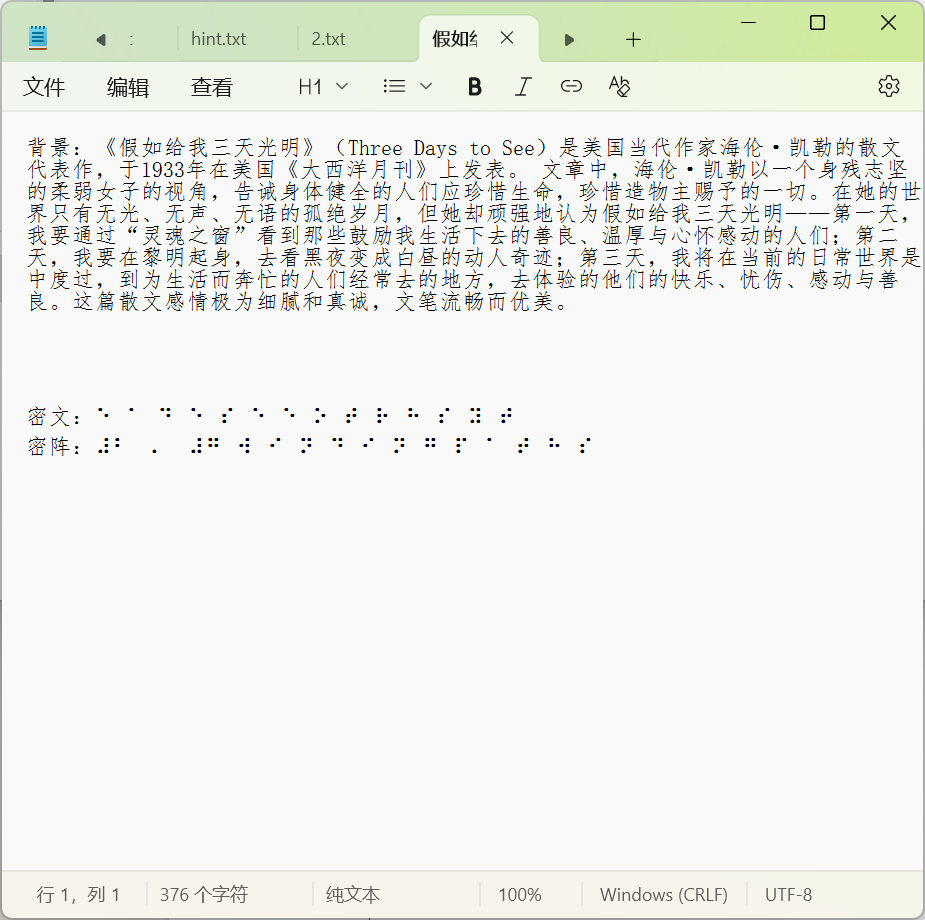
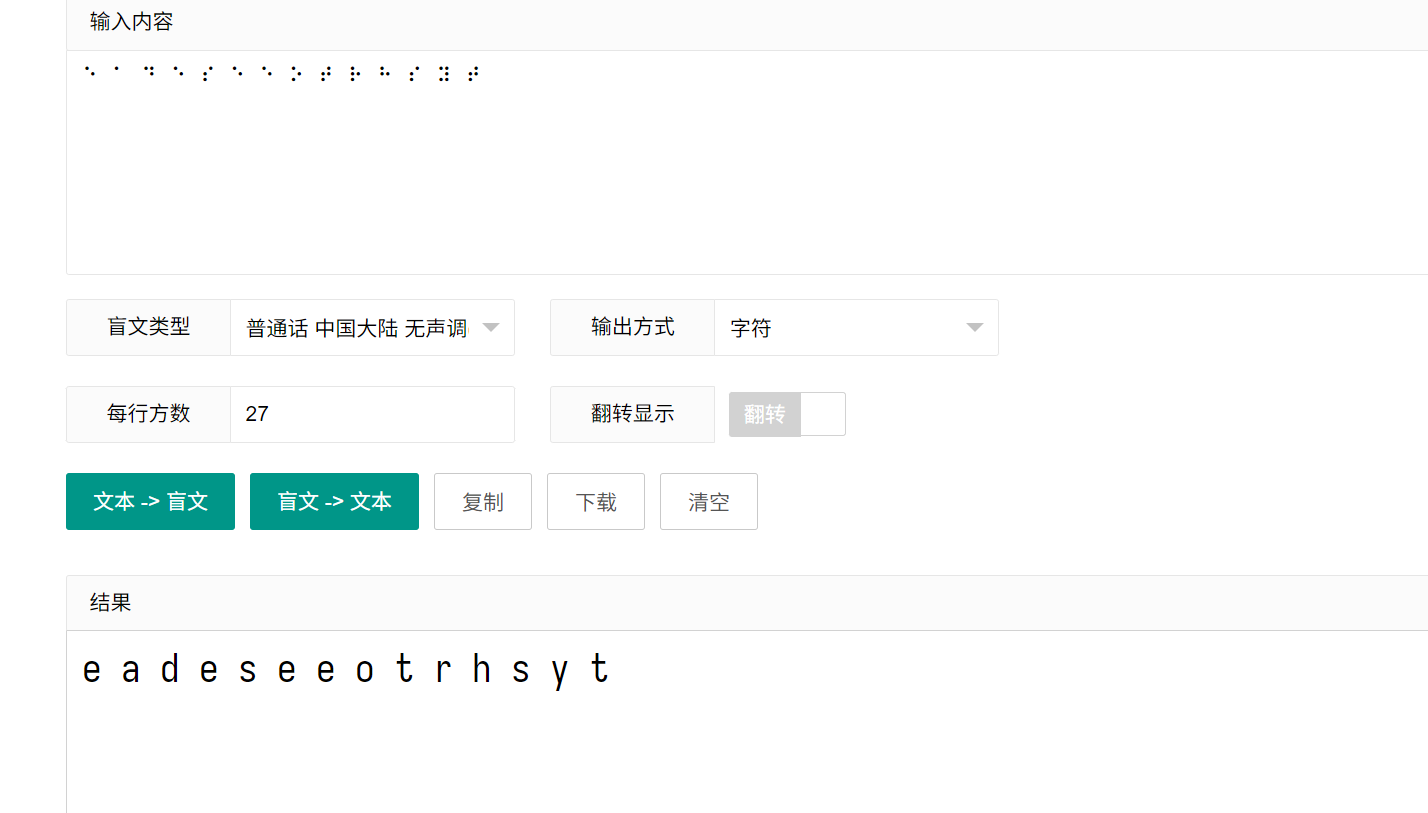
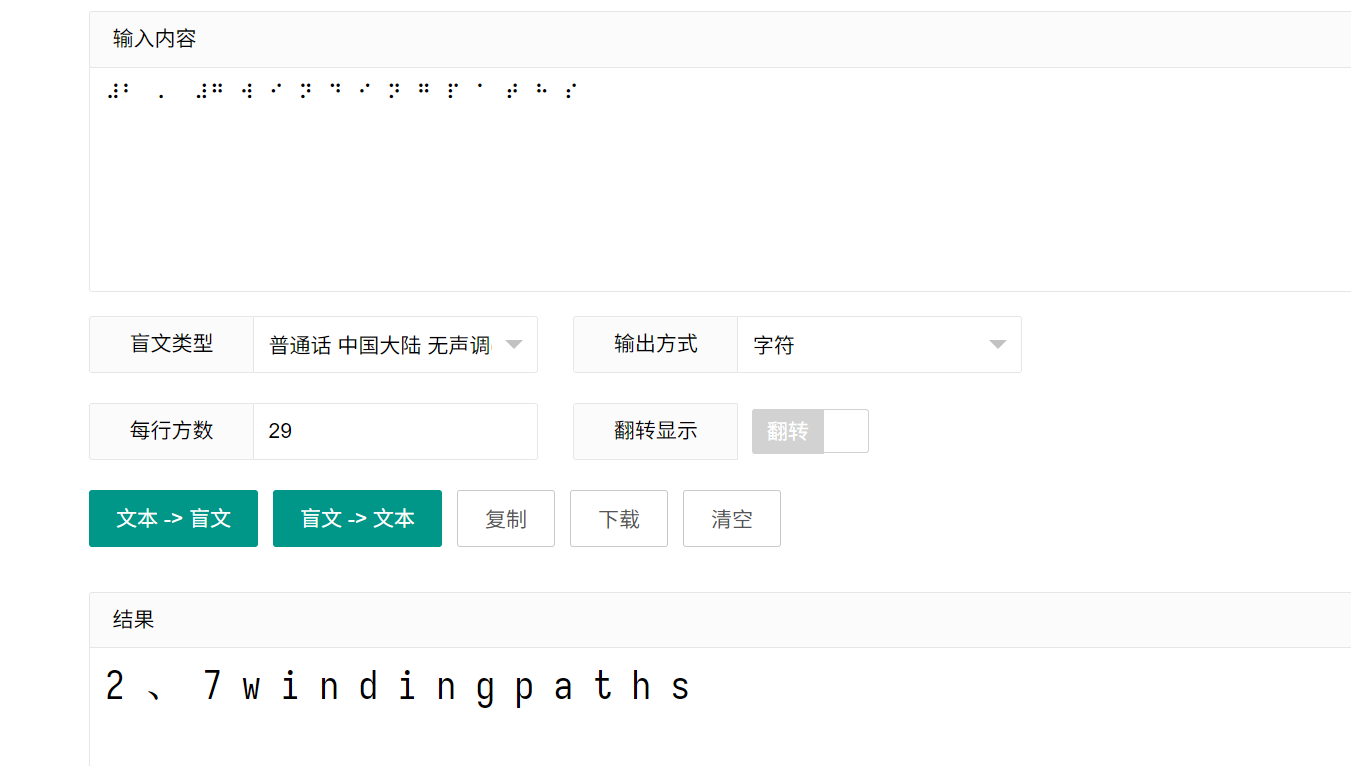
曲路密码解出来是threedaystosee,MD5加上flag{}即可
PloTS
6-1 小明爱跑步
这个附件可以在
https://gpx.studio/zh/app#11.82/36.63461/116.96134
中找到原始走的路径,根据要求我们选择其中几个特殊时间间隔来提取新的gpx文件,用ai帮忙按照可能的间隔分出来,放入在线地图,可以看到在间隔为2的gpx记录可以看到明确的路径画出的字母IO,转MD5提交即可。(附上分割gpx的脚本如下)
import xml.etree.ElementTree as ET
from datetime import datetime
import hashlib
def parse_gpx(file_path):
"""解析GPX文件,提取所有点的时间和坐标"""
try:
tree = ET.parse(file_path)
root = tree.getroot()
namespace = {'gpx': '[http://www.topografix.com/GPX/1/1'}](http://www.topografix.com/GPX/1/1'})
points = []
for trk in root.findall('.//gpx:trk', namespace):
for trkseg in trk.findall('.//gpx:trkseg', namespace):
for trkpt in trkseg.findall('.//gpx:trkpt', namespace):
time_elem = trkpt.find('gpx:time', namespace)
if time_elem is not None:
time_str = time_elem.text
# 解析时间戳
dt = datetime.fromisoformat(time_str.replace('Z', '+00:00'))
sec = dt.second # 提取秒数
lat = trkpt.get('lat')
lon = trkpt.get('lon')
points.append({
'lat': lat,
'lon': lon,
'time': dt,
'sec': sec
})
return points
except Exception as e:
print(f"解析GPX出错: {e}")
return []
def filter_points_by_seconds(points, sec_values):
"""根据秒数值筛选点"""
return [p for p in points if p['sec'] in sec_values]
def generate_new_gpx(points, output_file):
"""生成新的GPX文件"""
gpx = ET.Element('gpx', version="1.1", creator="GPX Filter Tool")
trk = ET.SubElement(gpx, 'trk')
trkseg = ET.SubElement(trk, 'trkseg')
for p in points:
trkpt = ET.SubElement(trkseg, 'trkpt', lat=p['lat'], lon=p['lon'])
time_elem = ET.SubElement(trkpt, 'time')
time_elem.text = p['time'].isoformat().replace('+00:00', 'Z')
tree = ET.ElementTree(gpx)
tree.write(output_file, encoding='utf-8', xml_declaration=True)
return output_file
def generate_md5(text):
"""生成MD5哈希值"""
return hashlib.md5(text.encode()).hexdigest()
def main():
# 解析原始GPX
points = parse_gpx('sport.gpx')
if not points:
print("未找到有效GPS点")
return
# 提取所有秒数,用于分析
all_seconds = [p['sec'] for p in points]
unique_sec = sorted(list(set(all_seconds)))
print(f"所有唯一秒数: {unique_sec}")
# 尝试不同的等差数列组合(处理用户示例中的模糊性)
# 可能的等差数列假设
candidates = [
{"name": "公差2(0,2,4...)", "sec_values": set(range(0, 60, 2))},
{"name": "公差3(0,3,6...)", "sec_values": set(range(0, 60, 3))},
{"name": "公差5(0,5,10...)", "sec_values": set(range(0, 60, 5))},
{"name": "用户示例(0,3,5)", "sec_values": {0, 3, 5}},
{"name": "秒数为0", "sec_values": {0}},
{"name": "秒数为5的倍数", "sec_values": {0,5,10,15,20,25,30,35,40,45,50,55}}
]
# 为每个候选生成筛选后的GPX
results = []
for candidate in candidates:
filtered = filter_points_by_seconds(points, candidate['sec_values'])
if filtered:
output_file = f"筛选结果_{candidate['name'].replace('(','_').replace(')','').replace(',','_').replace('...','')}.gpx"
generate_new_gpx(filtered, output_file)
results.append({
"name": candidate["name"],
"count": len(filtered),
"file": output_file
})
print(f"生成: {output_file} ({len(filtered)}个点)")
# 保存结果摘要
with open('筛选结果摘要.md', 'w', encoding='utf-8') as f:
f.write("# GPX筛选结果摘要\n\n")
f.write(f"原始GPX点数量: {len(points)}\n\n")
f.write("## 尝试的筛选条件及结果\n")
for res in results:
f.write(f"### {res['name']}\n")
f.write(f"- 筛选后点数量: {res['count']}\n")
f.write(f"- 生成文件: {res['file']}\n\n")
f.write("## 下一步建议\n")
f.write("1. 将生成的GPX文件导入地图软件查看轨迹形状\n")
f.write("2. 找到形成字母形状的轨迹对应的筛选条件\n")
f.write("3. 将识别出的字母进行MD5加密,使用网站:[https://crypot.51strive.com/md5.html\n")](https://crypot.51strive.com/md5.html\n"))
print("筛选结果摘要.md")
print("生成成功")
if name == "__main__":
main()
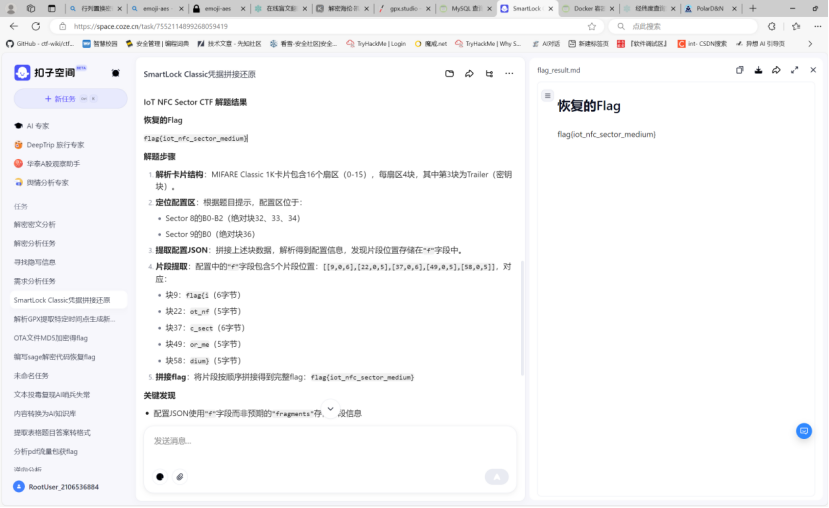
6-3 smartlock
直接给ai一把嗦了
解析卡片结构:MIFARE Classic 1K卡片包含16个扇区(0-15),每扇区4块,其中第3块为Trailer(密钥块)。
定位配置区:根据题目提示,配置区位于:
Sector 8的B0-B2(绝对块32、33、34)
Sector 9的B0(绝对块36)
提取配置JSON:拼接上述块数据,解析得到配置信息,发现片段位置存储在"f"字段中。
片段提取:配置中的"f"字段包含5个片段位置:[[9,0,6],[22,0,5],[37,0,6],[49,0,5],[58,0,5]],对应:
块9:flag{i(6字节)
块22:ot_nf(5字节)
块37:c_sect(6字节)
块49:or_me(5字节)
块58:dium}(5字节)
拼接flag:将片段按顺序拼接得到完整flag:flag{iot_nfc_sector_medium}
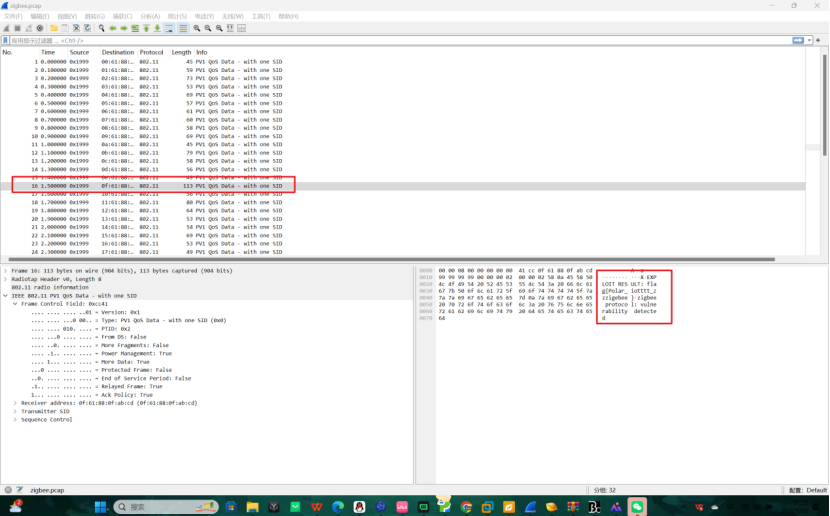
6-4 zigbee
流量包里明文存着的直接翻就行