排名猛猛掉,从二十多掉七十多,只能说py的力量太强了
差点ak misc 八卦还在追我()
misc部分
Terminal Hacker
很简单的签到题,顺着输入命令就能拿到flag,或者也可以直接逆,pyextractor解包反编译pyc即可。

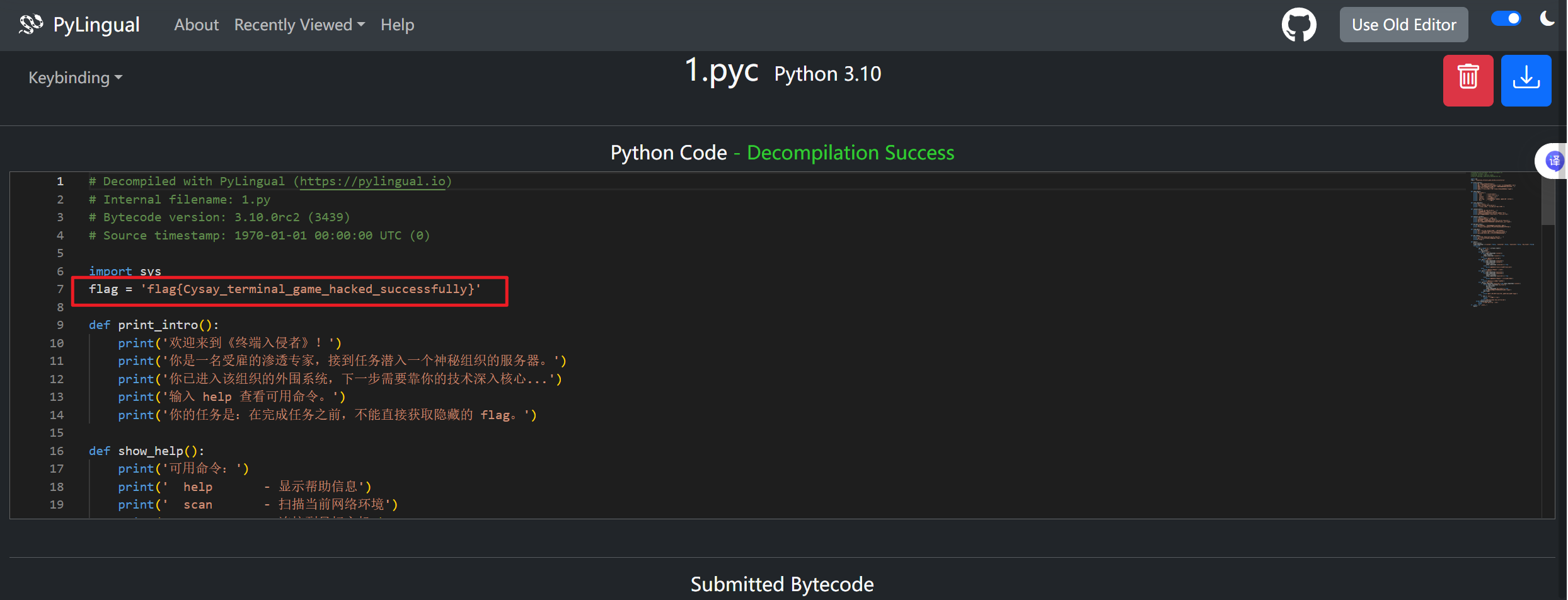
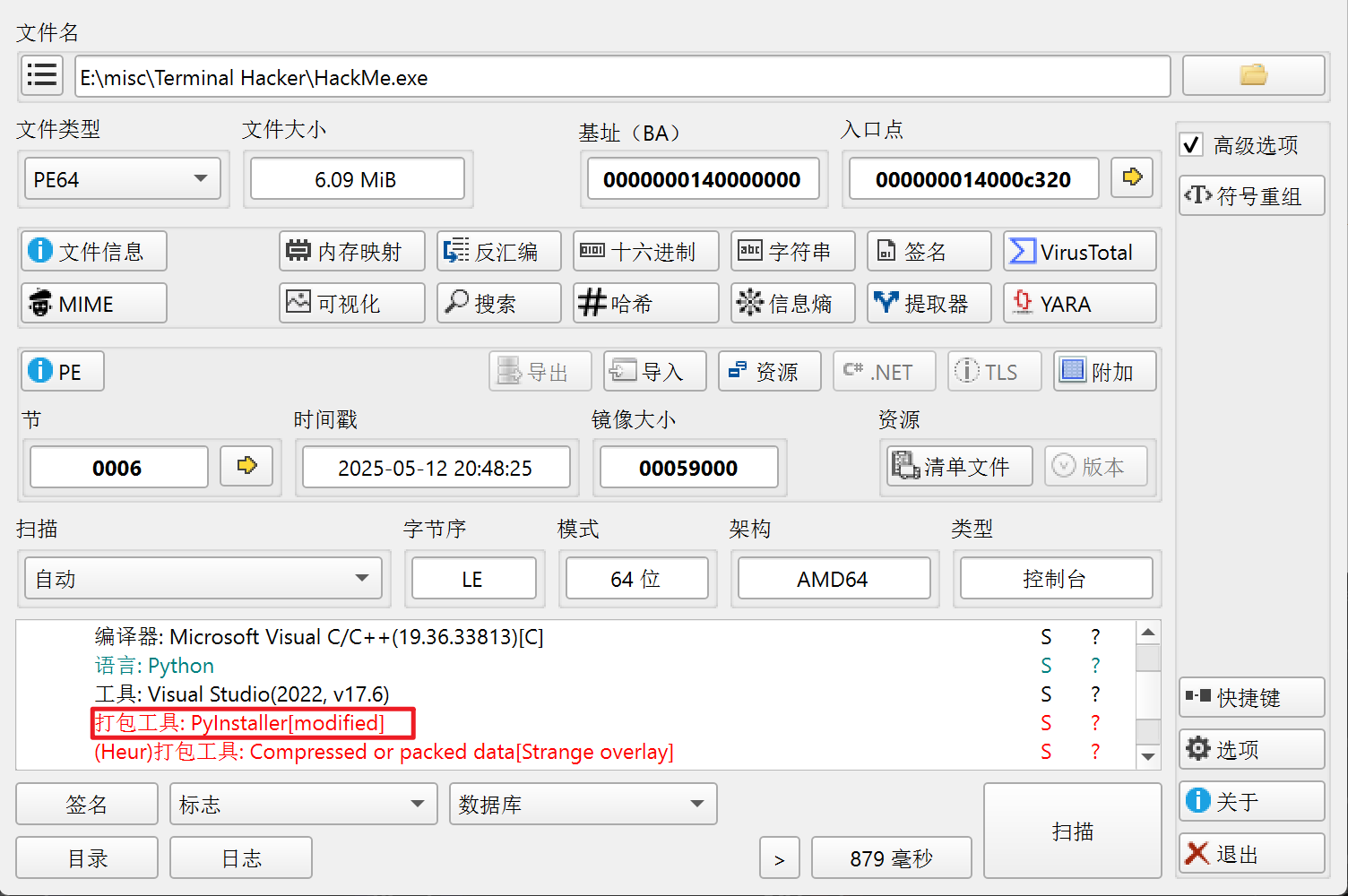 解包,反编译一下pyc即可,附上网站https://pylingual.io/
解包,反编译一下pyc即可,附上网站https://pylingual.io/
一大碗冰粉
内存取证题,注意观察题目说到桌面的秘密文件,还有提示,用lovelymem挂载一下镜像。
注意镜像是win10镜像,不能用vol2,这里使用memProcfs打开搜索全局文件,desktop关键字搜搜桌面文件有啥,可以发现有hint,根据路径查找到这个文件。
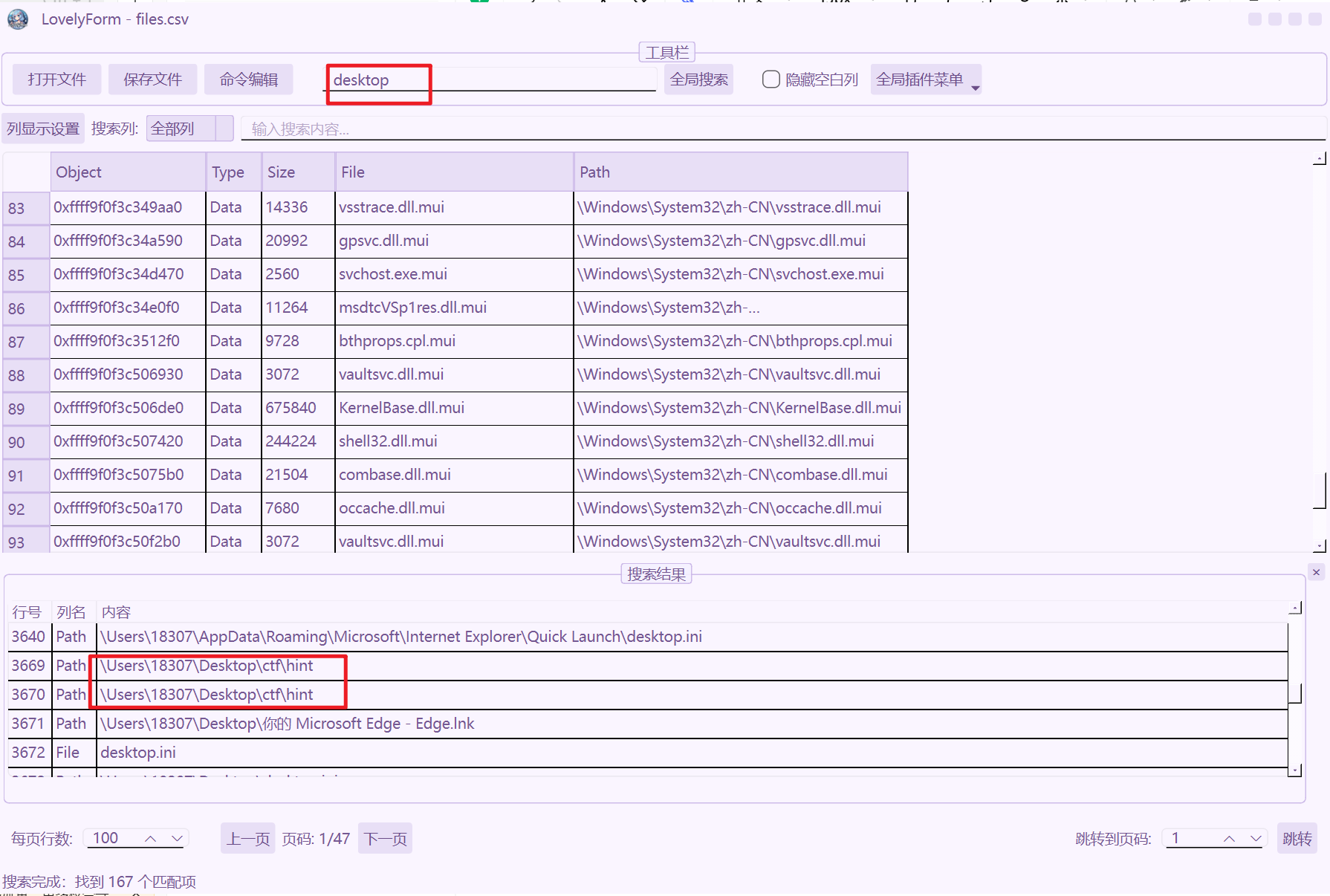
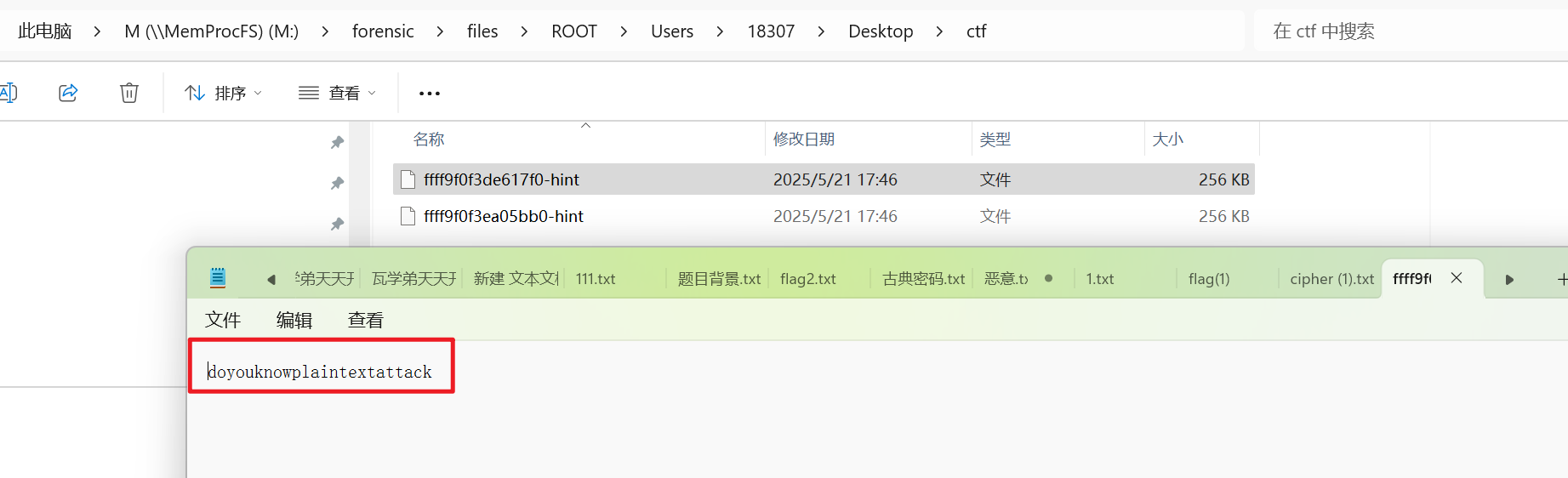
文件给了提示明文攻击,在上一级目录还存在一个压缩包带密码,且带hint.txt文件,拿bkcrack跑一下。
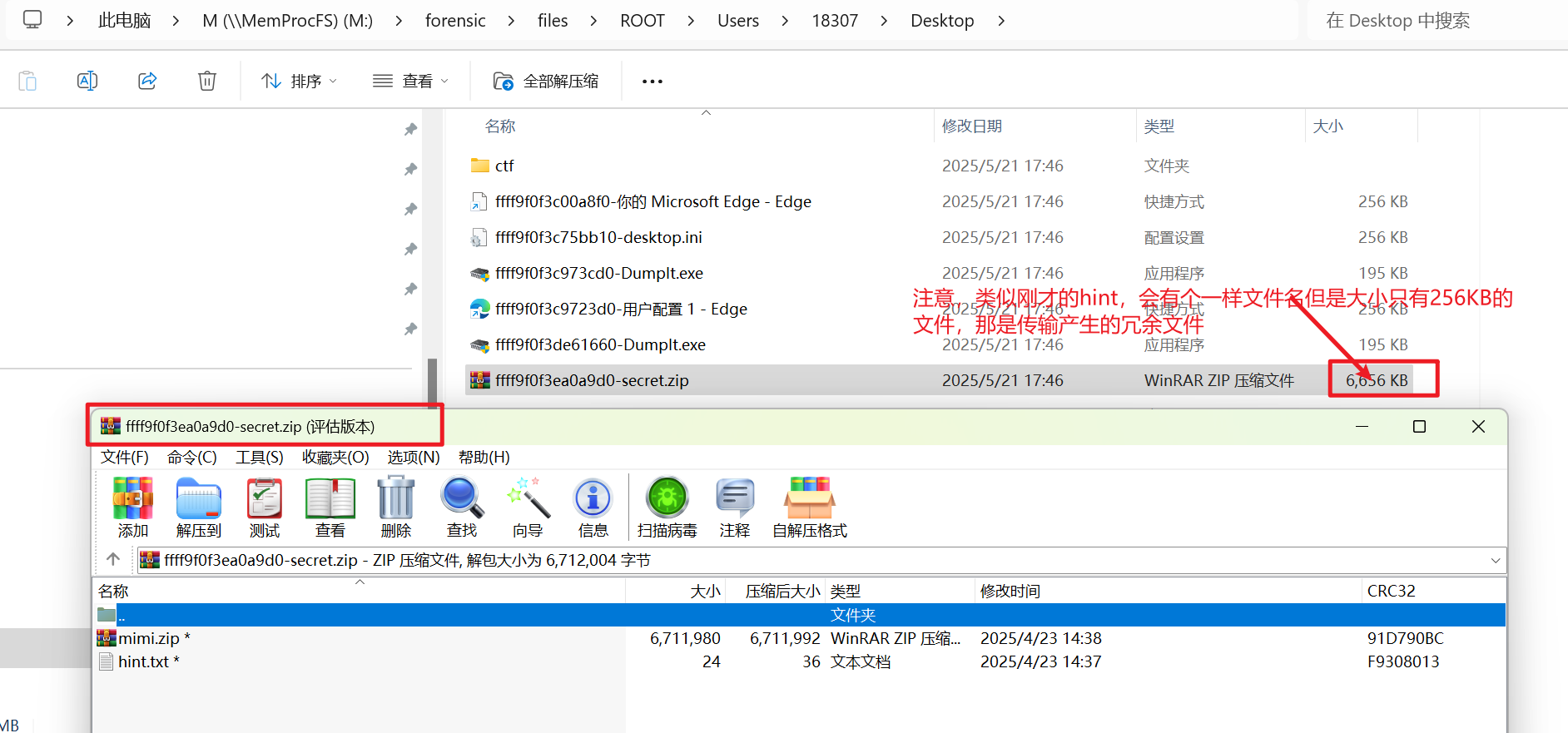
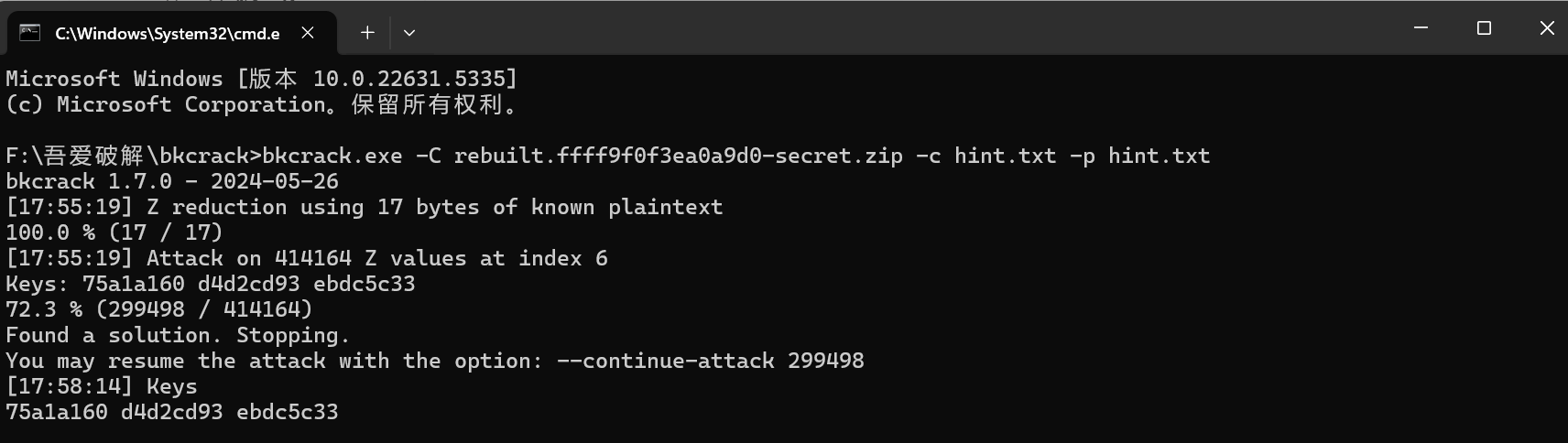
注意压缩包保险起见先用winrar的恢复重构功能恢复一下,防止存在压缩包损坏的情况,跑出key后直接导出去除密码的zip即可,解压里面的mini.zip,有个啥也不是的文件,010查看不存在任何文件头,观察文件名,尝试异或,key使用search,得到新压缩包。(开始我也很疑惑)
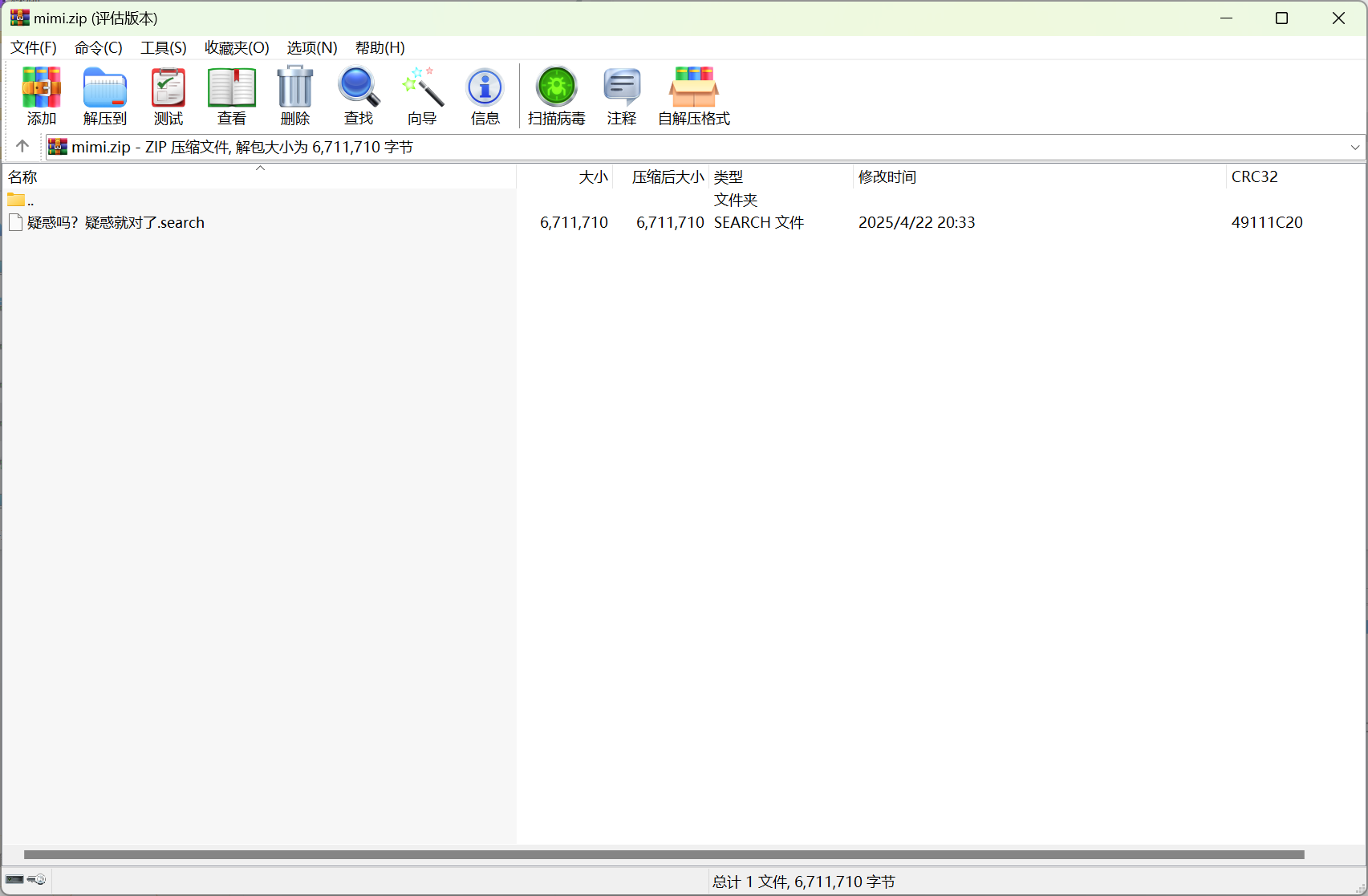

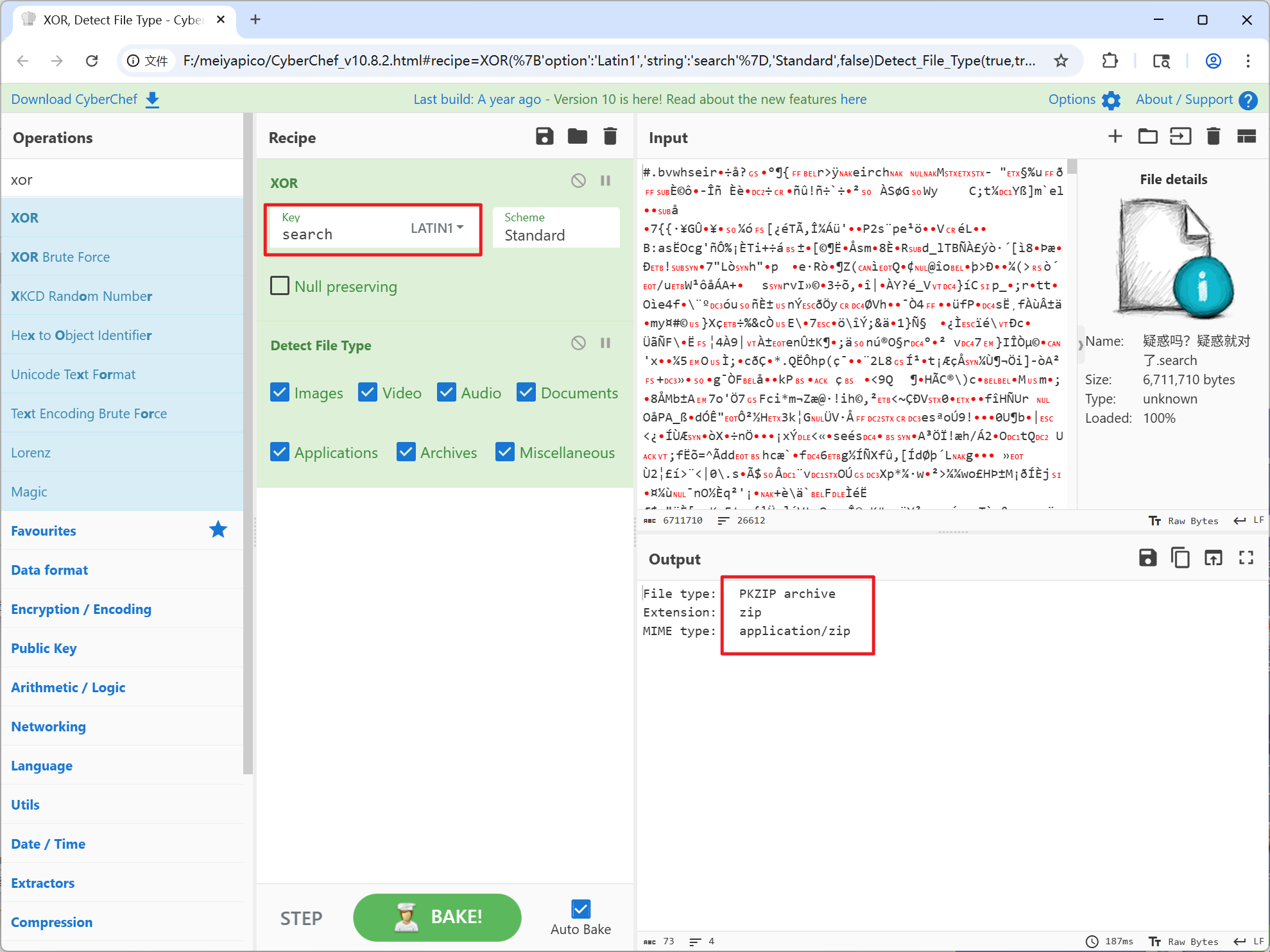
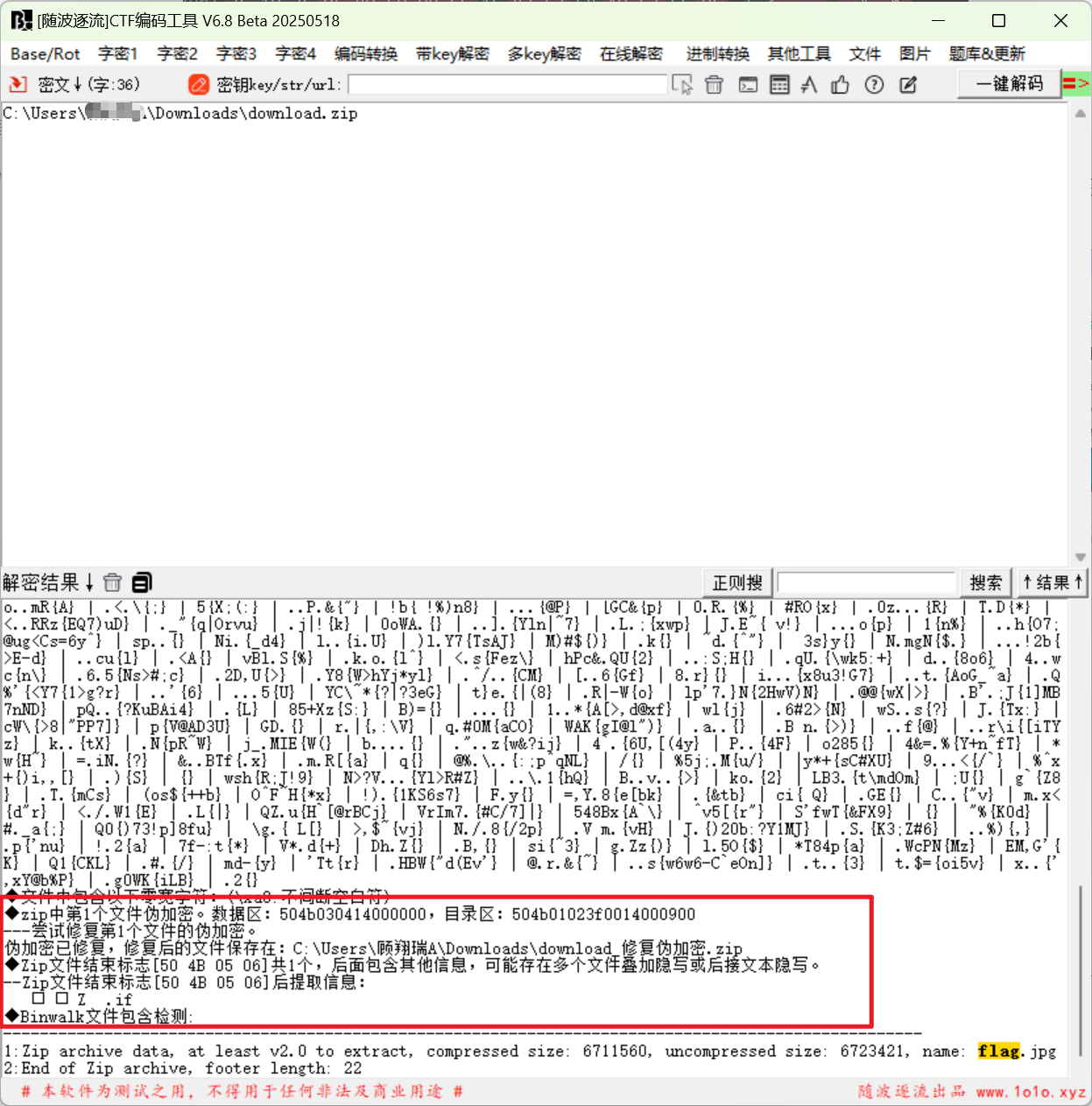
cyberchef解码出来保存打开这个zip,带加密,随波一下,不出意外的伪加密,修复一下,可以得到一张图片,随波逐流能看到写的提示flag格式。
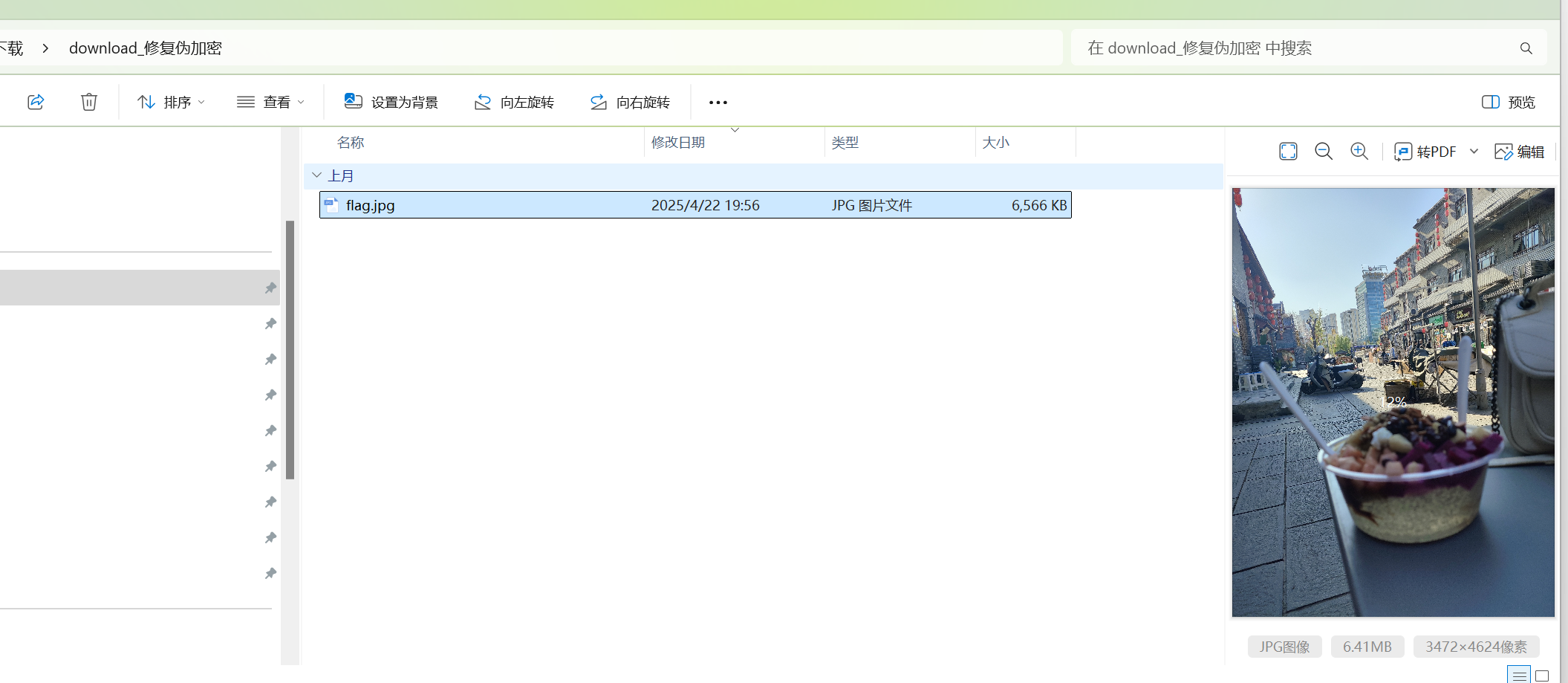
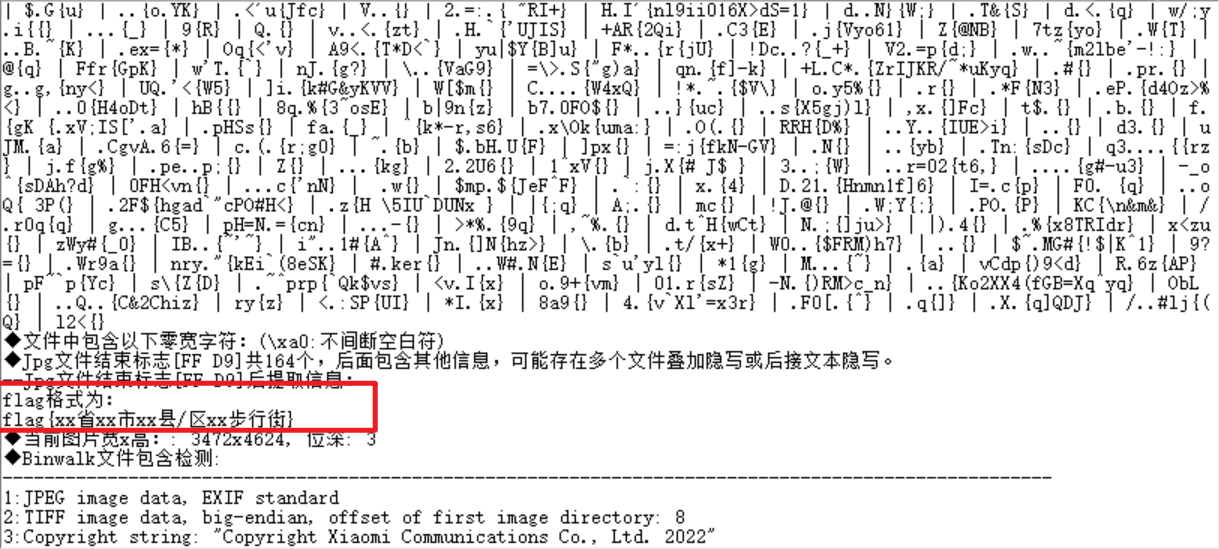
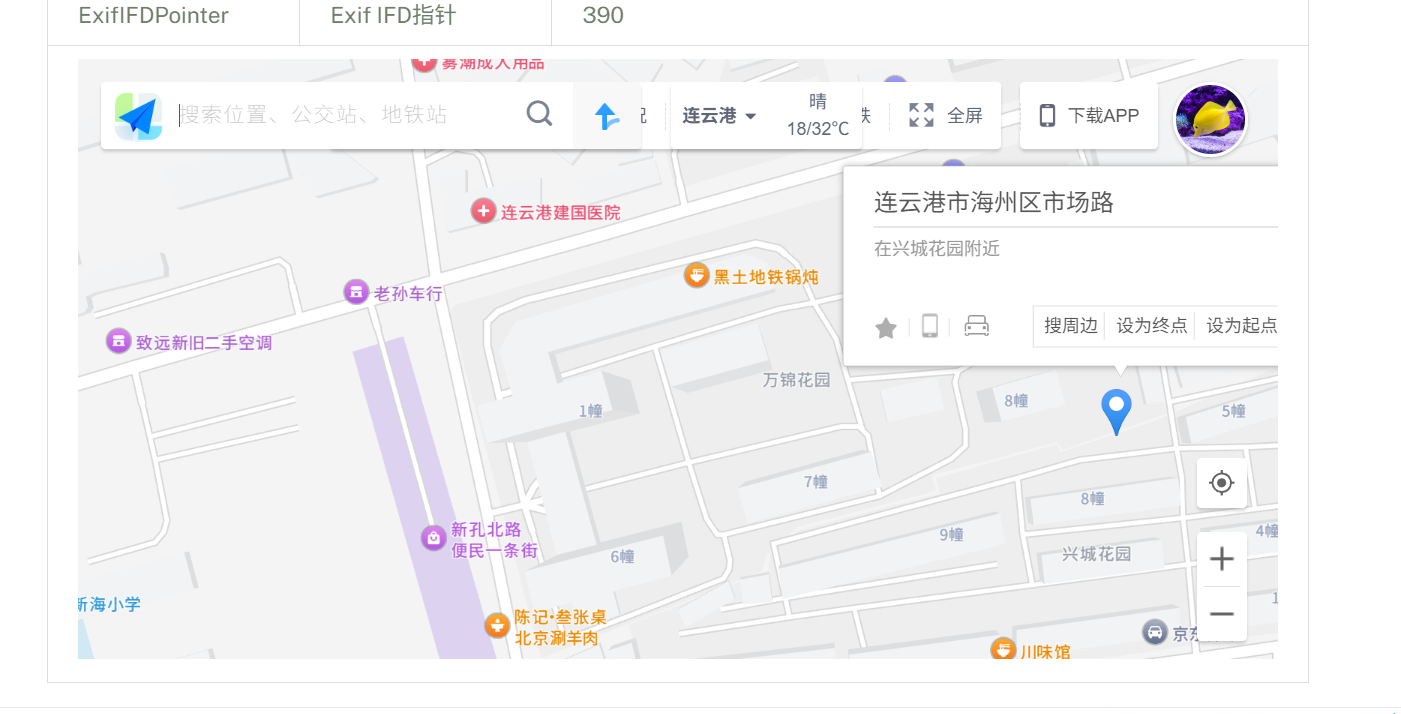
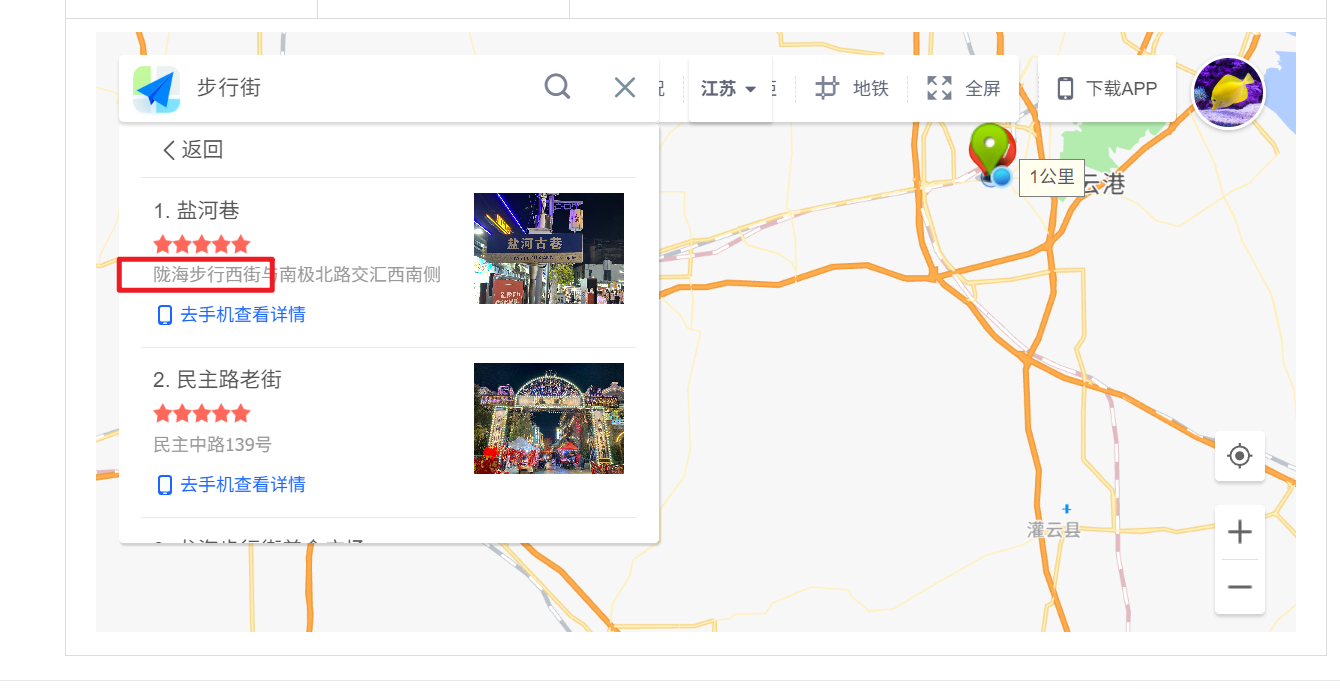
很明显的社工题了,根据exif信息定位到江苏省连云港市海州区,根据背景的酒店名字搜附近得到是陇海步行街。flag{江苏省连云港市海州区陇海步行街}
哇哇哇瓦
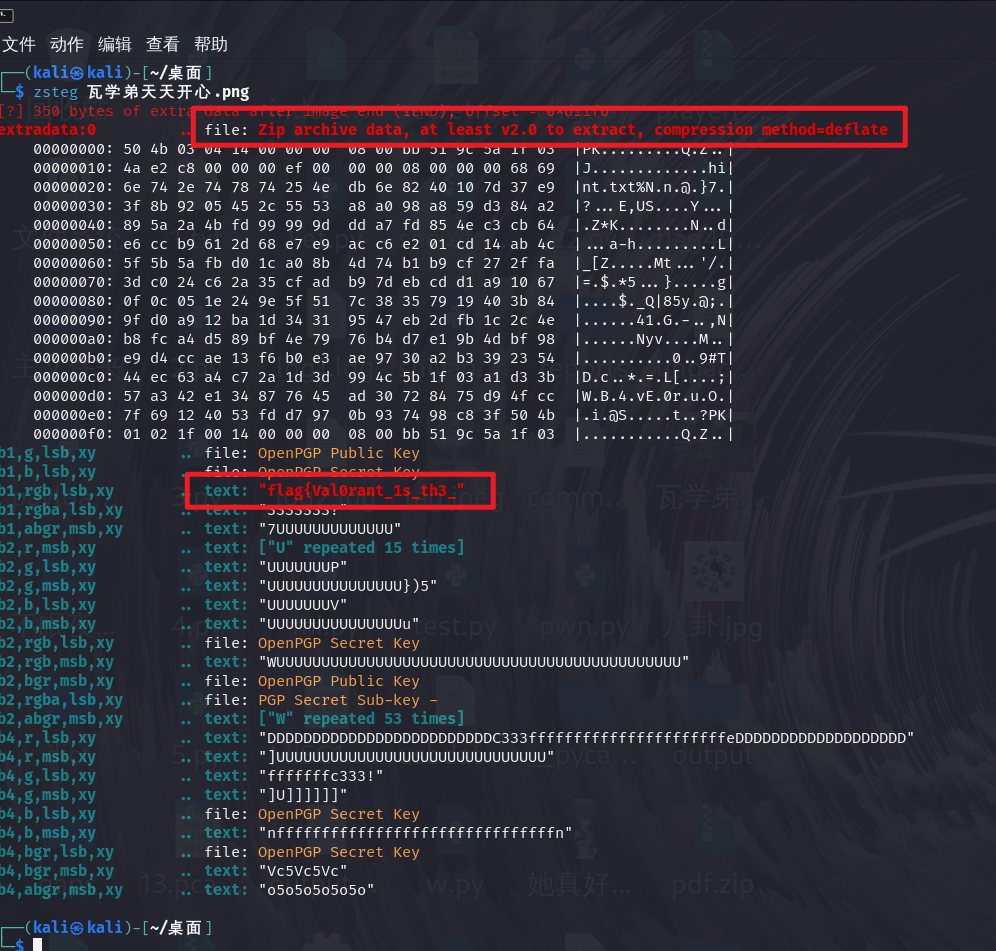
一张图片,zsteg直接拿到一半的flag,另外发现有隐写的压缩包,foremost提取一下即可,得到提示。

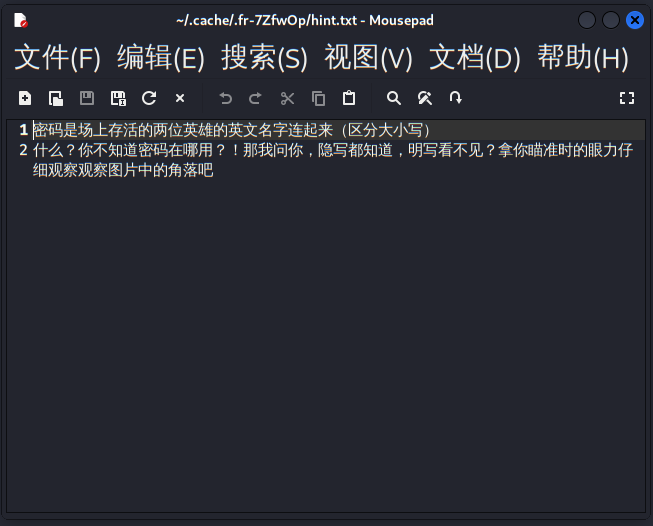
通过打瓦的室友获取密码为GekkoYoru,观察到角落有最低位隐写的特点,stegsolver提取一下,得到一个逆序的压缩包,puzzle solver倒序获得flag第二半。
 flag{Val0rant_1s_th3_best_FPS_g@me!!}
flag{Val0rant_1s_th3_best_FPS_g@me!!}
音频的秘密
摩斯直接转就是假的flag,观察ad里的波形图,有干扰,尝试用silenteye提取,选择低精度,可以得到一个压缩包,提示Lovely,图片压缩包可以爆破,密码为1234.

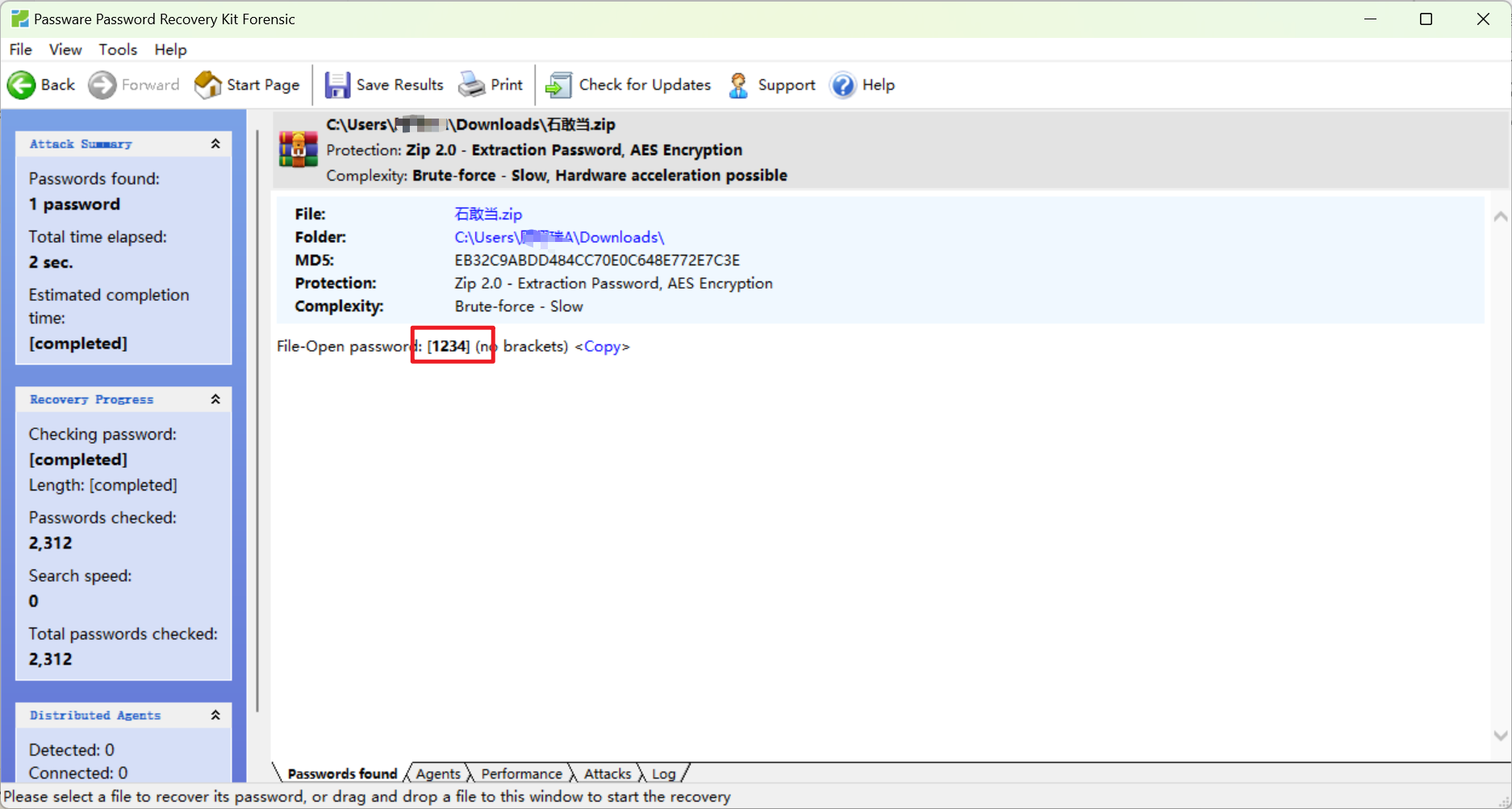
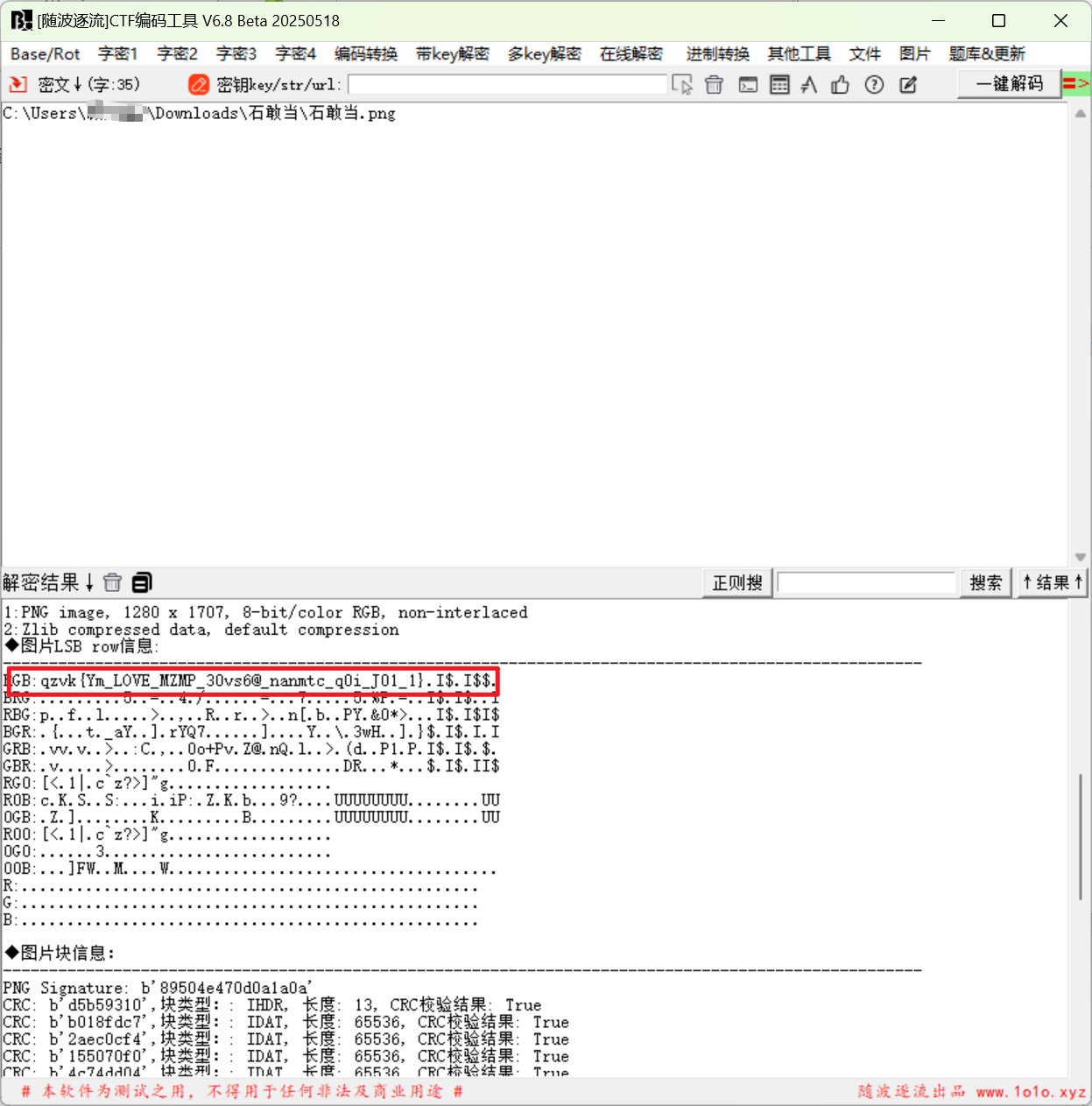
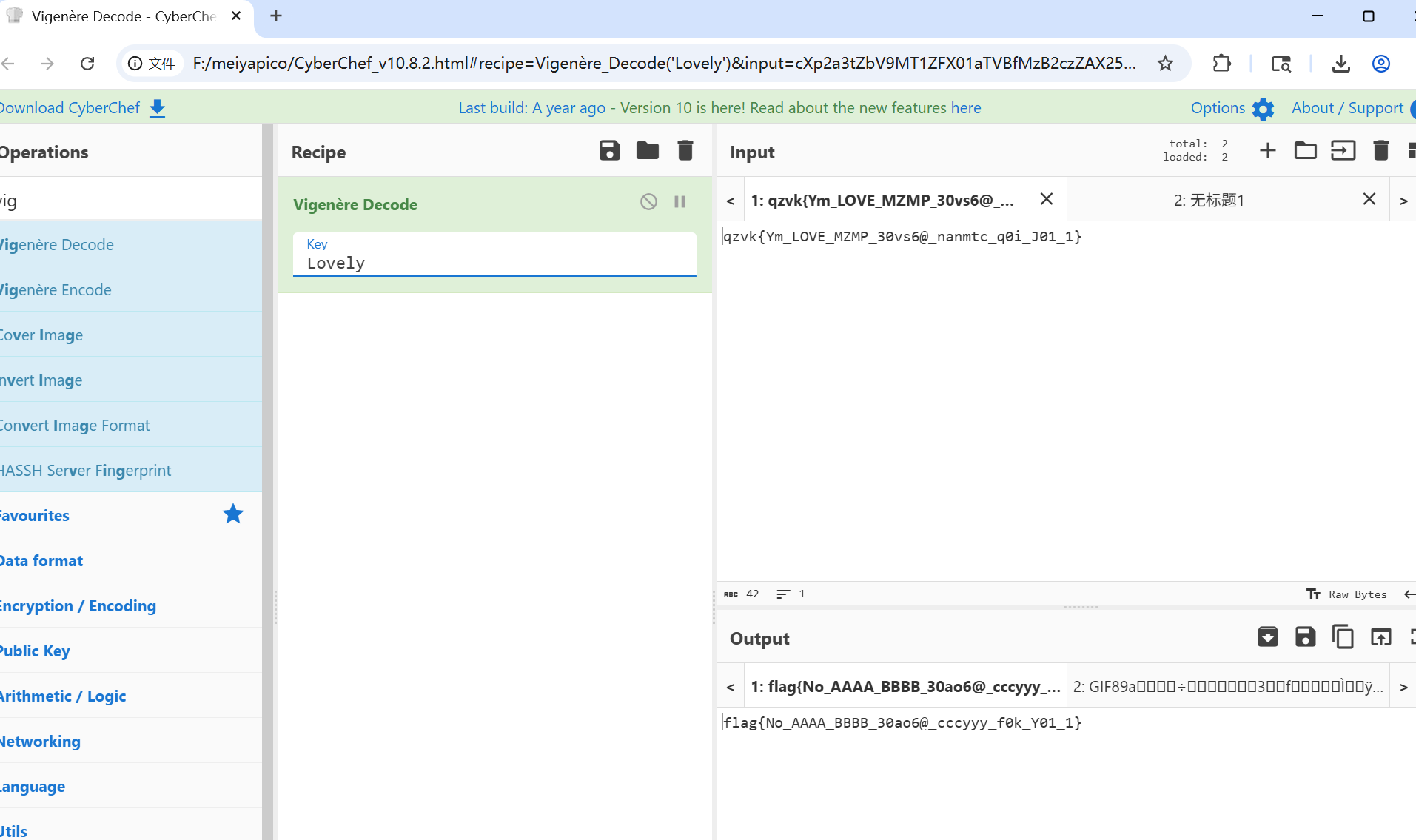
解压图片,可以发现rgb输出有类似flag的字符串,结合没用的key:Lovely,维戈尼亚解密一下得到flag
数据识别和审计
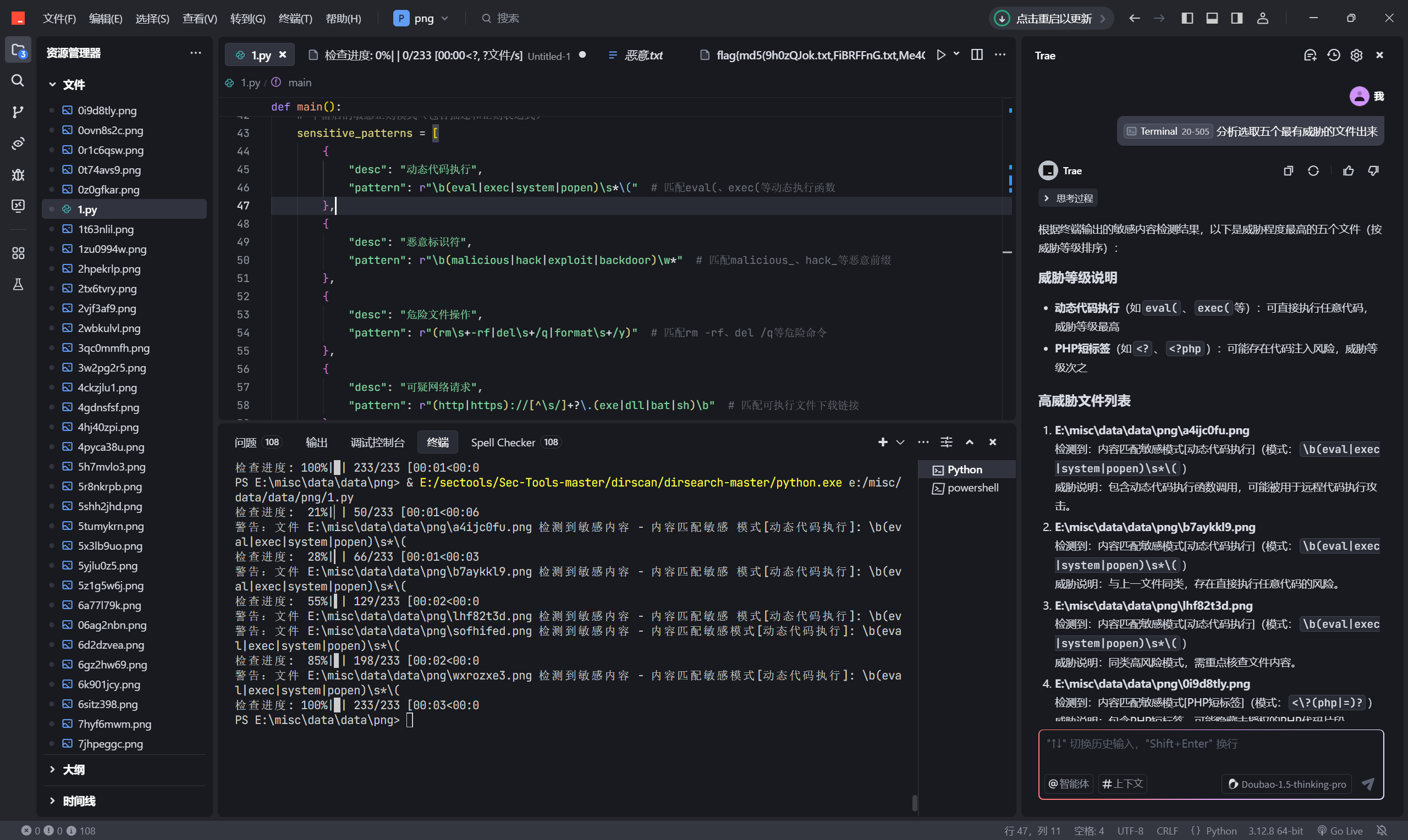
图片写脚本发现带恶意代码正则,txt过滤带数字和字母,pdf用pdfid导出信息后写脚本筛选带js的文件,wav是通过010一个个看,有存在数据的就是目标文件。
import os
import re # 新增:正则表达式库
from PIL import Image
from PIL.ExifTags import TAGS
from tqdm import tqdm
def check_sensitive_content(file_path, sensitive_patterns):
# 检查文件内容是否包含敏感正则模式
try:
with open(file_path, 'rb') as f:
content = f.read()
content_str = content.decode('utf-8', errors='ignore')
for pattern_info in sensitive_patterns:
pattern = pattern_info["pattern"]
desc = pattern_info["desc"]
if re.search(pattern, content_str, re.IGNORECASE): # 忽略大小写匹配
return True, f"内容匹配敏感模式[{desc}]: {pattern}"
except Exception as e:
return False, f"读取文件失败: {str(e)}"
# 检查图片元数据(EXIF)是否包含敏感正则模式
try:
img = Image.open(file_path)
exif_data = img.getexif()
if exif_data:
for tag_id in exif_data:
tag = TAGS.get(tag_id, tag_id)
value = exif_data.get(tag_id)
if isinstance(value, str):
for pattern_info in sensitive_patterns:
pattern = pattern_info["pattern"]
desc = pattern_info["desc"]
if re.search(pattern, value, re.IGNORECASE):
return True, f"元数据[{tag}]匹配敏感模式[{desc}]: {pattern}"
except Exception as e:
return False, f"读取元数据失败: {str(e)}"
return False, "未发现敏感内容"
def main():
target_dir = os.getcwd()
# 丰富后的敏感正则模式(包含描述和正则表达式)
sensitive_patterns = [
{
"desc": "动态代码执行",
"pattern": r"\b(eval|exec|system|popen)\s*\(" # 匹配eval(、exec(等动态执行函数
},
{
"desc": "恶意标识符",
"pattern": r"\b(malicious|hack|exploit|backdoor)\w*" # 匹配malicious_、hack_等恶意前缀
},
{
"desc": "危险文件操作",
"pattern": r"(rm\s+-rf|del\s+/q|format\s+/y)" # 匹配rm -rf、del /q等危险命令
},
{
"desc": "可疑网络请求",
"pattern": r"(http|https)://[^\s/]+?\.(exe|dll|bat|sh)\b" # 匹配可执行文件下载链接
}
]
# 收集当前目录及子目录下所有PNG文件(用于进度条总数计算)
png_files = []
for root, _, files in os.walk(target_dir): # 修改:遍历子目录
for f in files:
if f.lower().endswith('.png'):
png_files.append(os.path.join(root, f)) # 记录完整路径
if not png_files:
print("未找到任何PNG文件(包括子目录)")
return
# 使用tqdm显示进度条(修改:显示完整路径)
for file_path in tqdm(png_files, desc="检查进度", unit="文件"):
is_sensitive, reason = check_sensitive_content(file_path, sensitive_patterns)
if is_sensitive:
print(f"\n警告:文件 {file_path} 检测到敏感内容 - {reason}")
if __name__ == "__main__":
main()png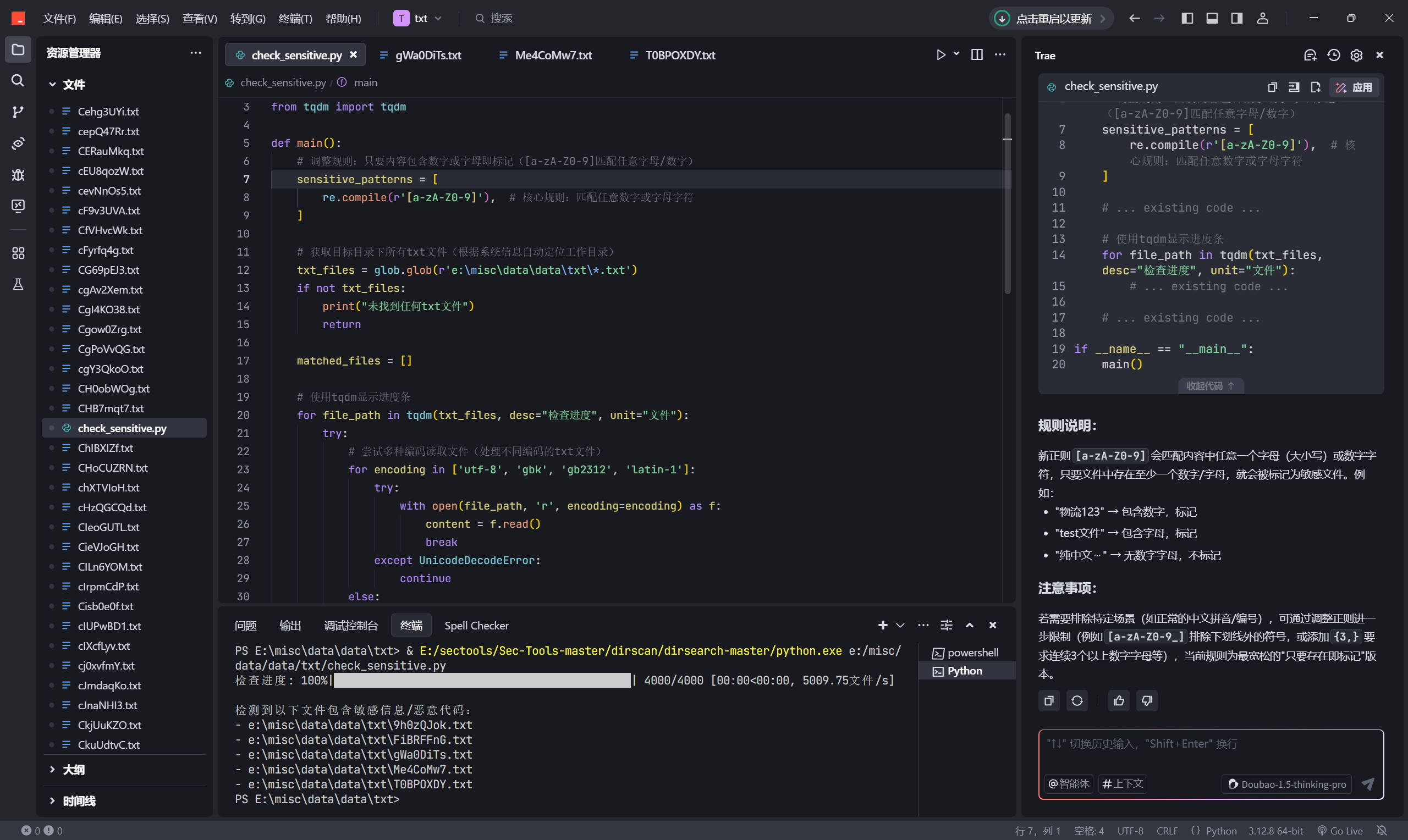
import glob
import re
from tqdm import tqdm
def main():
# 调整规则:只要内容包含数字或字母即标记([a-zA-Z0-9]匹配任意字母/数字)
sensitive_patterns = [
re.compile(r'[a-zA-Z0-9]'), # 核心规则:匹配任意数字或字母字符
]
# 获取目标目录下所有txt文件(根据系统信息自动定位工作目录)
txt_files = glob.glob(r'e:\misc\data\data\txt\*.txt')
if not txt_files:
print("未找到任何txt文件")
return
matched_files = []
# 使用tqdm显示进度条
for file_path in tqdm(txt_files, desc="检查进度", unit="文件"):
try:
# 尝试多种编码读取文件(处理不同编码的txt文件)
for encoding in ['utf-8', 'gbk', 'gb2312', 'latin-1']:
try:
with open(file_path, 'r', encoding=encoding) as f:
content = f.read()
break
except UnicodeDecodeError:
continue
else:
raise ValueError("无法识别的文件编码")
# 检查是否匹配任意敏感模式
for pattern in sensitive_patterns:
if pattern.search(content):
matched_files.append(file_path)
break # 只要匹配一个模式就停止检查当前文件
except Exception as e:
print(f"\n警告:处理文件 {file_path} 时发生错误: {str(e)}")
# 输出结果
if matched_files:
print("\n检测到以下文件包含敏感信息/恶意代码:")
for file in matched_files:
print(f"- {file}")
else:
print("\n未检测到敏感信息或恶意代码")
if __name__ == "__main__":
main()txt
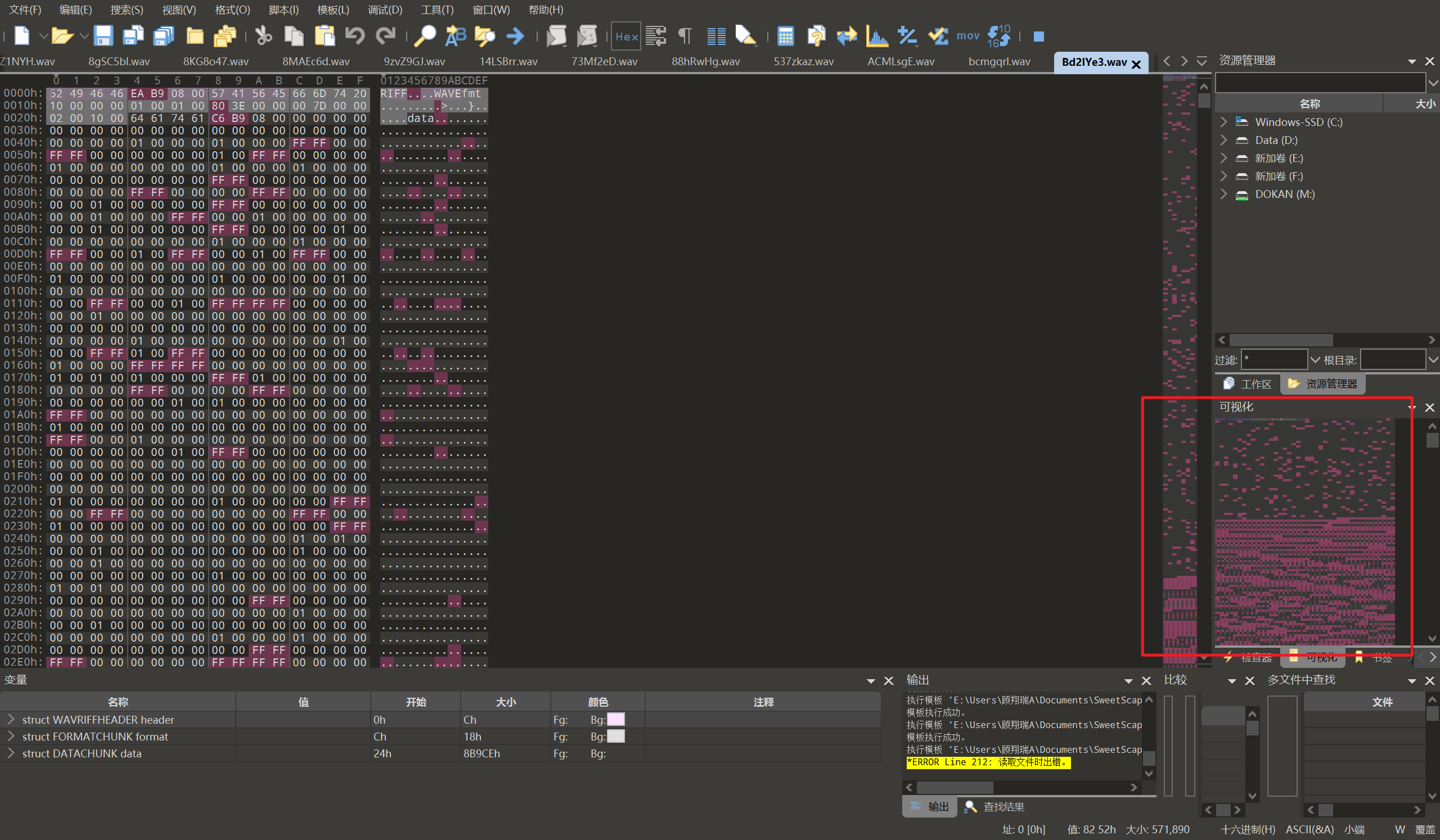
注意看可视化有数据的就是有信息的wav

命令导出来信息
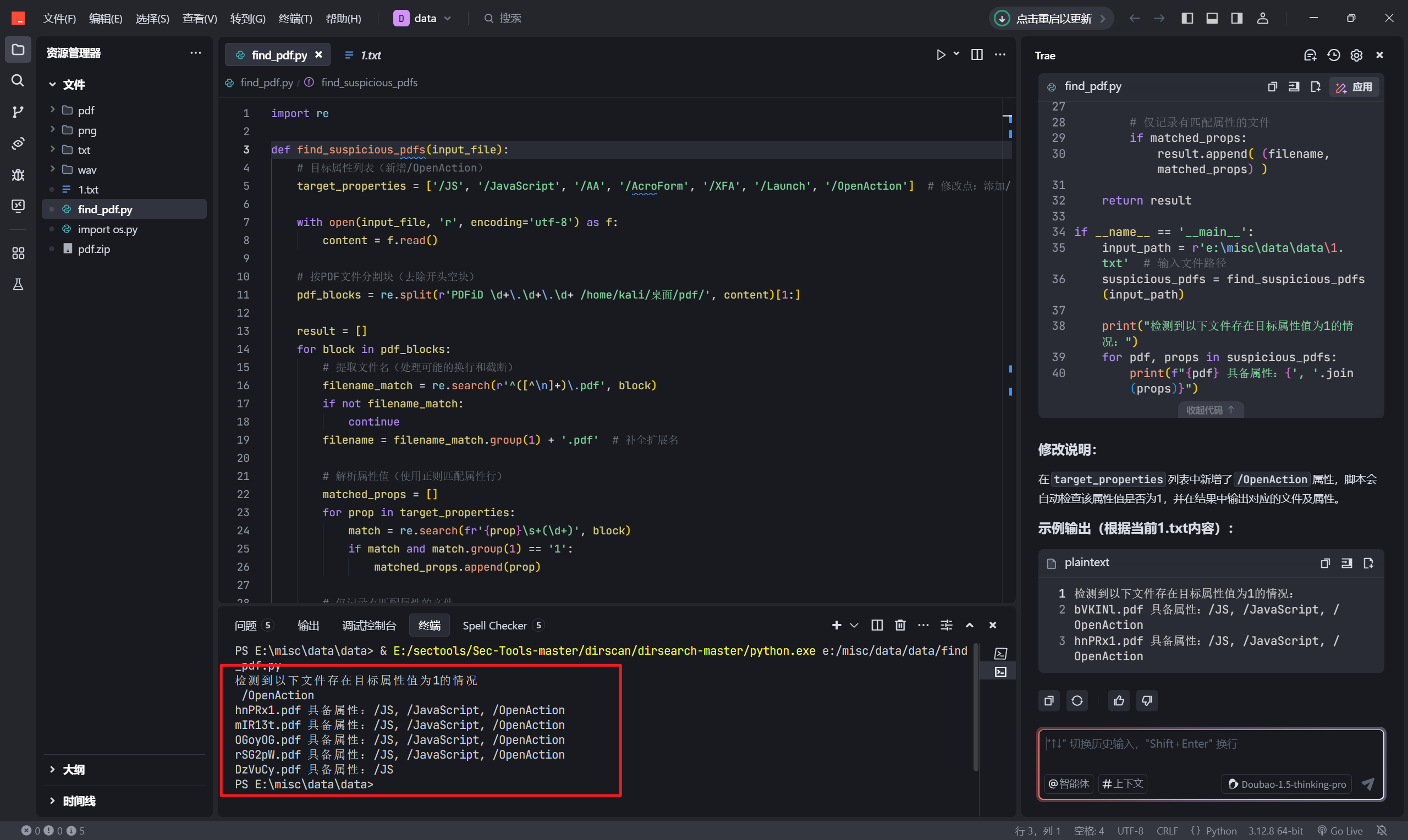
import re
def find_suspicious_pdfs(input_file):
# 目标属性列表(新增/OpenAction)
target_properties = ['/JS', '/JavaScript', '/AA', '/AcroForm', '/XFA', '/Launch', '/OpenAction'] # 修改点:添加/OpenAction
with open(input_file, 'r', encoding='utf-8') as f:
content = f.read()
# 按PDF文件分割块(去除开头空块)
pdf_blocks = re.split(r'PDFiD \d+\.\d+\.\d+ /home/kali/桌面/pdf/', content)[1:]
result = []
for block in pdf_blocks:
# 提取文件名(处理可能的换行和截断)
filename_match = re.search(r'^([^\n]+)\.pdf', block)
if not filename_match:
continue
filename = filename_match.group(1) + '.pdf' # 补全扩展名
# 解析属性值(使用正则匹配属性行)
matched_props = []
for prop in target_properties:
match = re.search(fr'{prop}\s+(\d+)', block)
if match and match.group(1) == '1':
matched_props.append(prop)
# 仅记录有匹配属性的文件
if matched_props:
result.append( (filename, matched_props) )
return result
if __name__ == '__main__':
input_path = r'e:\misc\data\data\1.txt' # 输入文件路径
suspicious_pdfs = find_suspicious_pdfs(input_path)
print("检测到以下文件存在目标属性值为1的情况:")
for pdf, props in suspicious_pdfs:
print(f"{pdf} 具备属性:{', '.join(props)}")隐藏的邀请
docx文档特性,改后缀为zip打开,发现一个不是原来配置文件的xml,解压出来010查看。
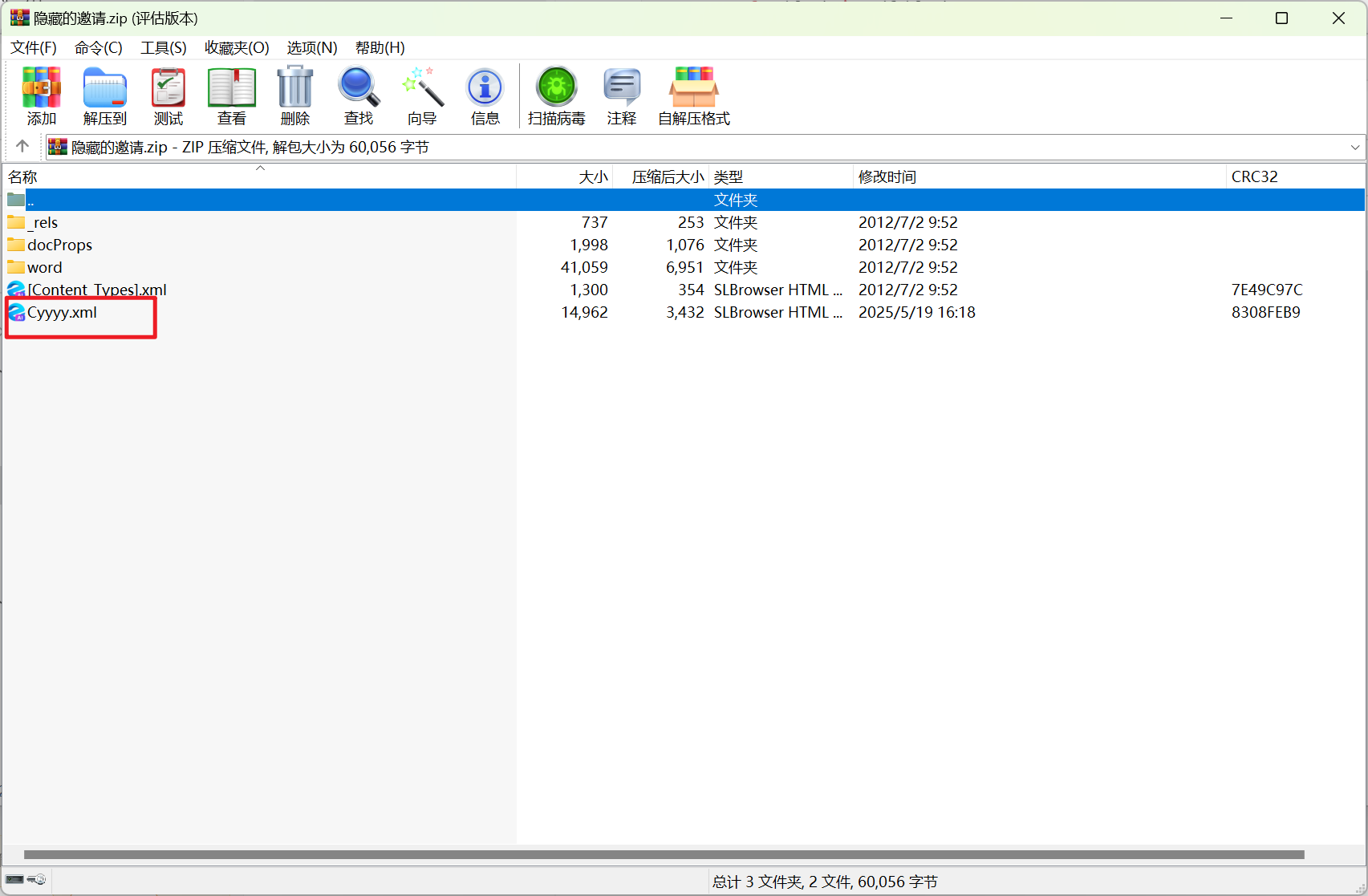
有一些奇怪的数据,提取出来到十六进制文件。
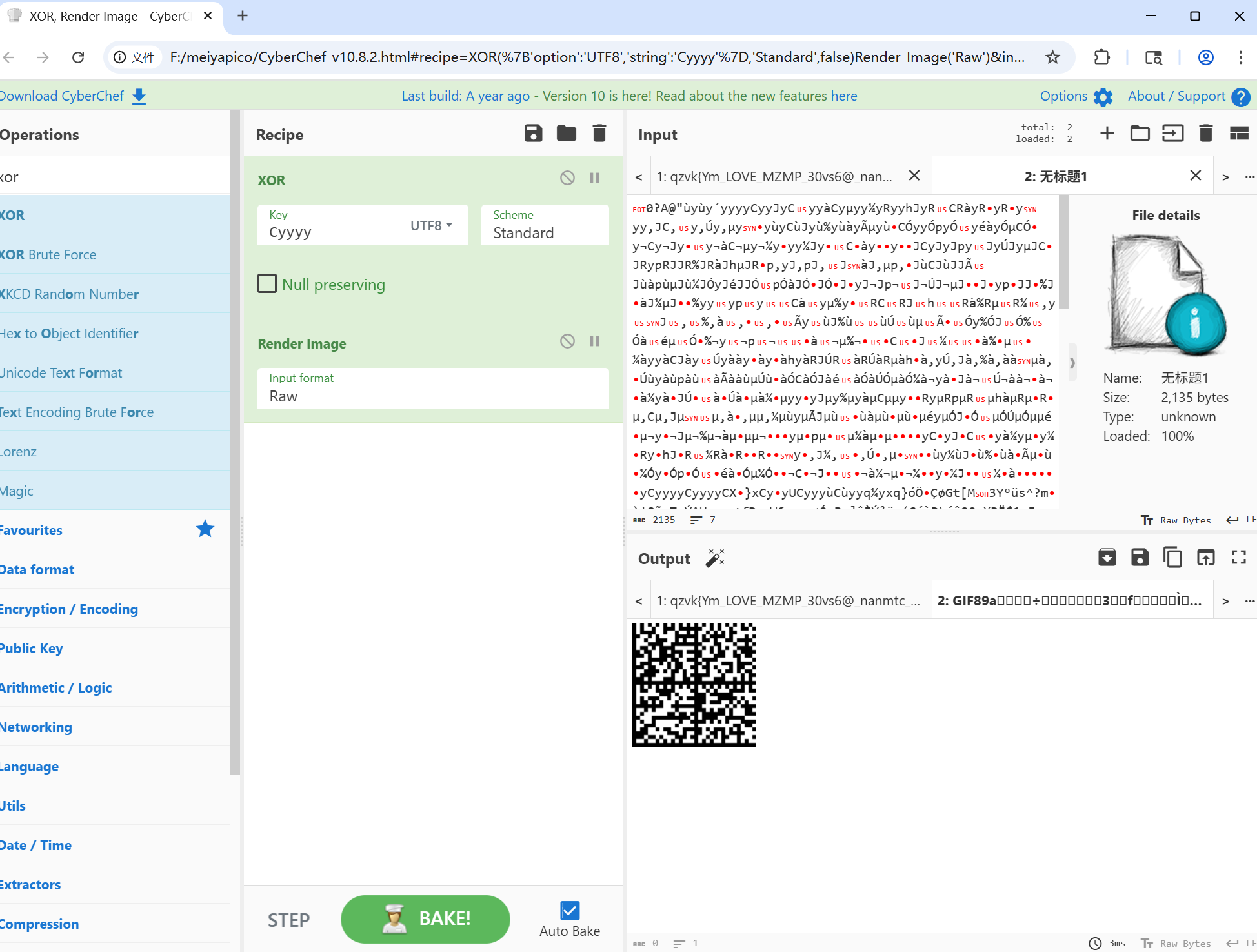
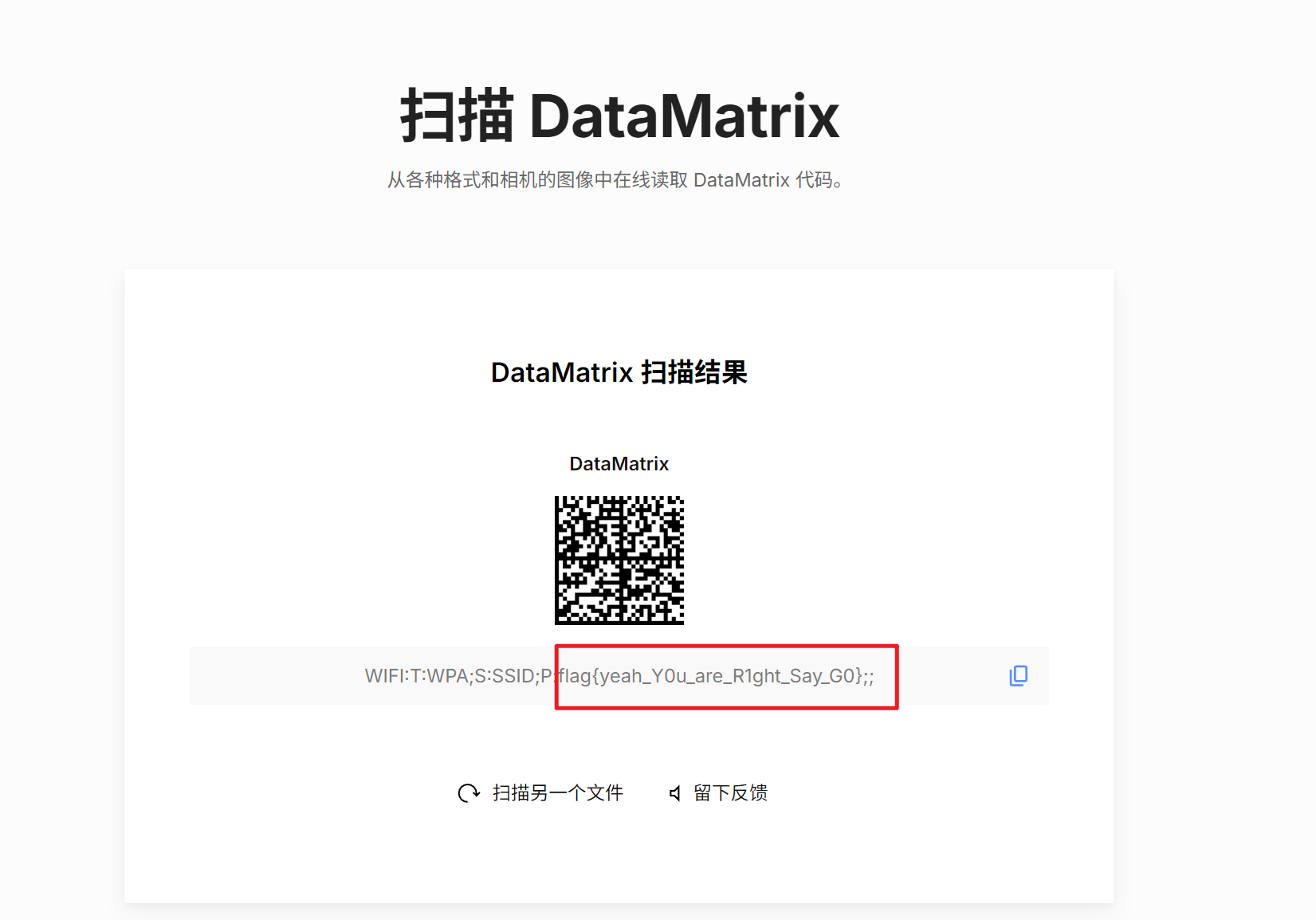
一是发现有很多cy,加上前面的经验,异或一下发现是一个data码,解码得到flag。
crypt
dp
直接拷打ai给脚本
 from Crypto.Util.number import long_to_bytes
from Crypto.Util.number import long_to_bytes
from gmpy2 import invert, is_prime, iroot
RSA参数
n = 110231451148882079381796143358970452100202953702391108796134950841737642949460527878714265898036116331356438846901198470479054762675790266666921561175879745335346704648242558094026330525194100460497557690574823790674495407503937159099381516207615786485815588440939371996099127648410831094531405905724333332751
dp = 3086447084488829312768217706085402222803155373133262724515307236287352098952292947424429554074367555883852997440538764377662477589192987750154075762783925
c = 59325046548488308883386075244531371583402390744927996480498220618691766045737849650329706821216622090853171635701444247741920578127703036446381752396125610456124290112692914728856924559989383692987222821742728733347723840032917282464481629726528696226995176072605314263644914703785378425284460609365608120126
e = 65537
使用dp恢复p
def recover_p():
for k in range(1, e):
if (dp * e - 1) % k == 0:
hp = (dp * e - 1) // k
p_candidate = hp + 1
if n % p_candidate == 0 and is_prime(p_candidate):
return p_candidate
return None
恢复p
p = recover_p()
if p is None:
print("无法恢复素数p")
else:
# 计算q
q = n // p
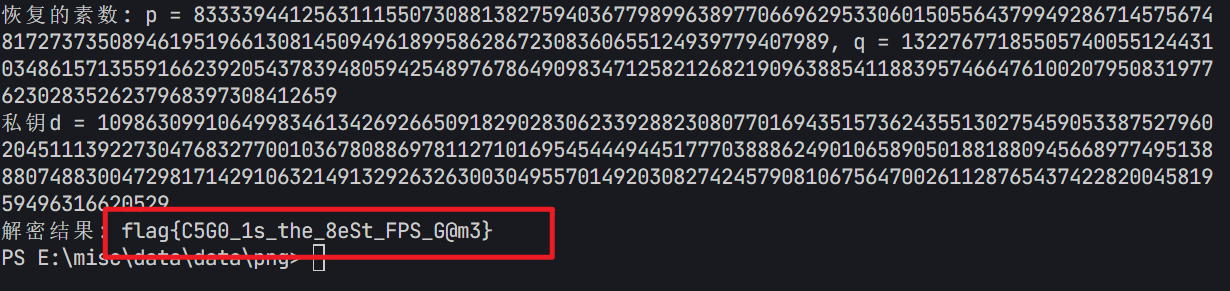
print(f"恢复的素数: p = {p}, q = {q}")
# 计算phi(n)
phi = (p - 1) * (q - 1)
# 计算私钥d
d = invert(e, phi)
print(f"私钥d = {d}")
# 解密消息
m = pow(c, d, n)
try:
flag = long_to_bytes(m)
print(f"解密结果: {flag.decode()}")
except:
print(f"解密后的字节: {m}")
print("无法解码为字符串,可能需要尝试其他方法")
easy_rsa
拷打ai即可
def extended_gcd(a, b):
if a == 0:
return (b, 0, 1)
else:
g, y, x = extended_gcd(b % a, a)
return (g, x - (b // a) * y, y)
def modinv(a, m):
g, x, y = extended_gcd(a, m)
if g != 1:
raise Exception('Modular inverse does not exist')
else:
return x % m
给定的参数
e = 65537
n = 1000000000000000000000000000156000000000000000000000000005643
c = 418535905348643941073541505434424306523376401168593325605206
p = 1000000000000000000000000000099
q = 1000000000000000000000000000057
计算phi(n)
phi_n = (p - 1) * (q - 1)
计算私钥d
d = modinv(e, phi_n)
还原明文
m = pow(c, d, n)
转换为ASCII字符串
try:
plaintext = m.to_bytes((m.bit_length() + 7) // 8, 'big').decode('ascii')
print(f"明文 (ASCII): {plaintext}") except UnicodeDecodeError:
print(f"明文 (十进制): {m}")
print("无法将明文转换为ASCII字符串,可能是因为包含非ASCII字符。")

web
ezjs
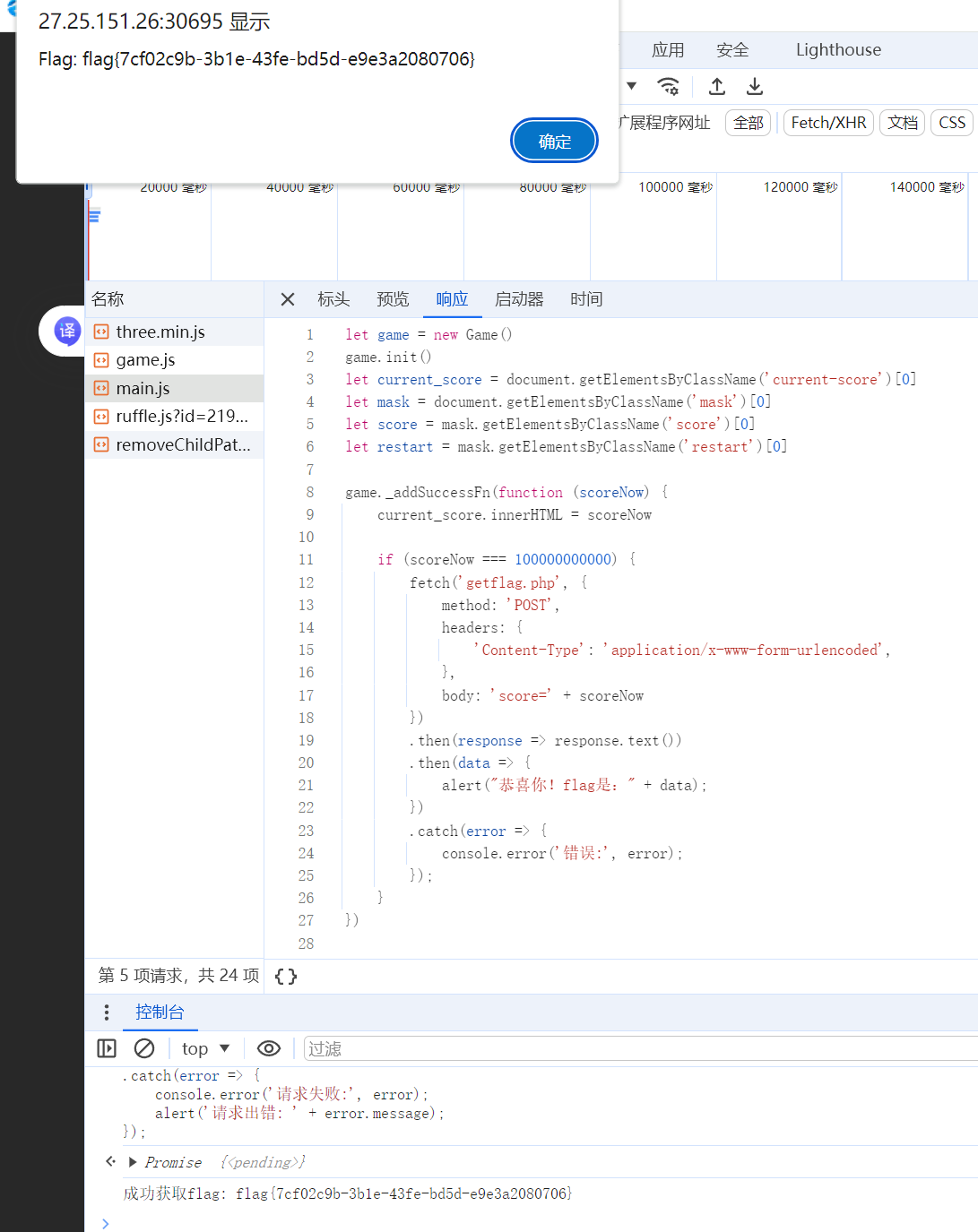
查看源代码,发现提交逻辑是分数到达一定给flag,直接发包就好
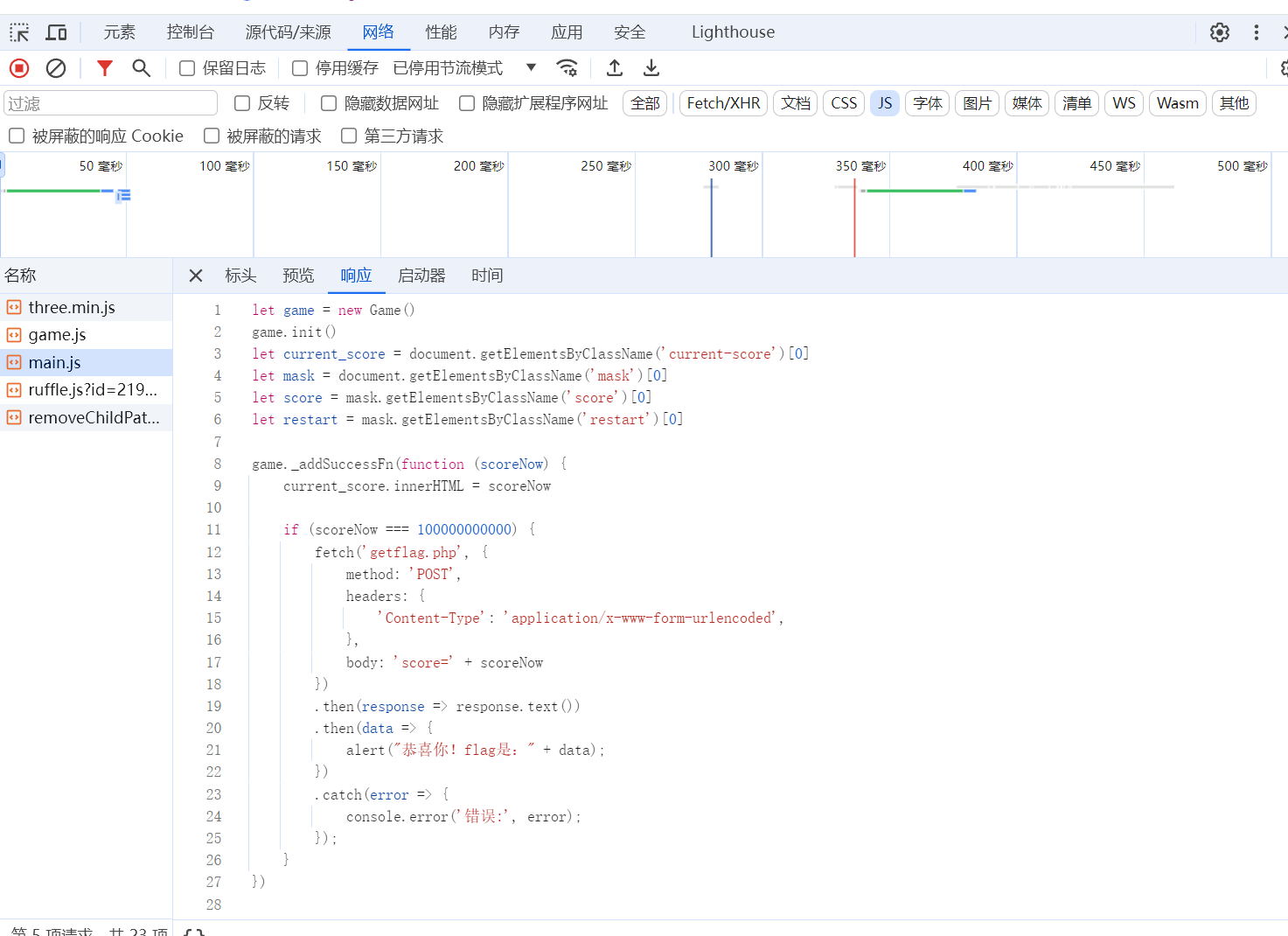 // 模拟游戏达到指定分数后触发的POST请求 fetch('getflag.php', { method: 'POST', headers: { 'Content-Type': 'application/x-www-form-urlencoded', }, body: 'score=100000000000' // 直接传递目标分数值 }) .then(response => { if (!response.ok) throw new Error(
// 模拟游戏达到指定分数后触发的POST请求 fetch('getflag.php', { method: 'POST', headers: { 'Content-Type': 'application/x-www-form-urlencoded', }, body: 'score=100000000000' // 直接传递目标分数值 }) .then(response => { if (!response.ok) throw new Error(HTTP错误,状态码: ${response.status}); return response.text(); }) .then(data => { console.log("成功获取flag:", data); alert("Flag: " + data); }) .catch(error => { console.error('请求失败:', error); alert('请求出错: ' + error.message); });
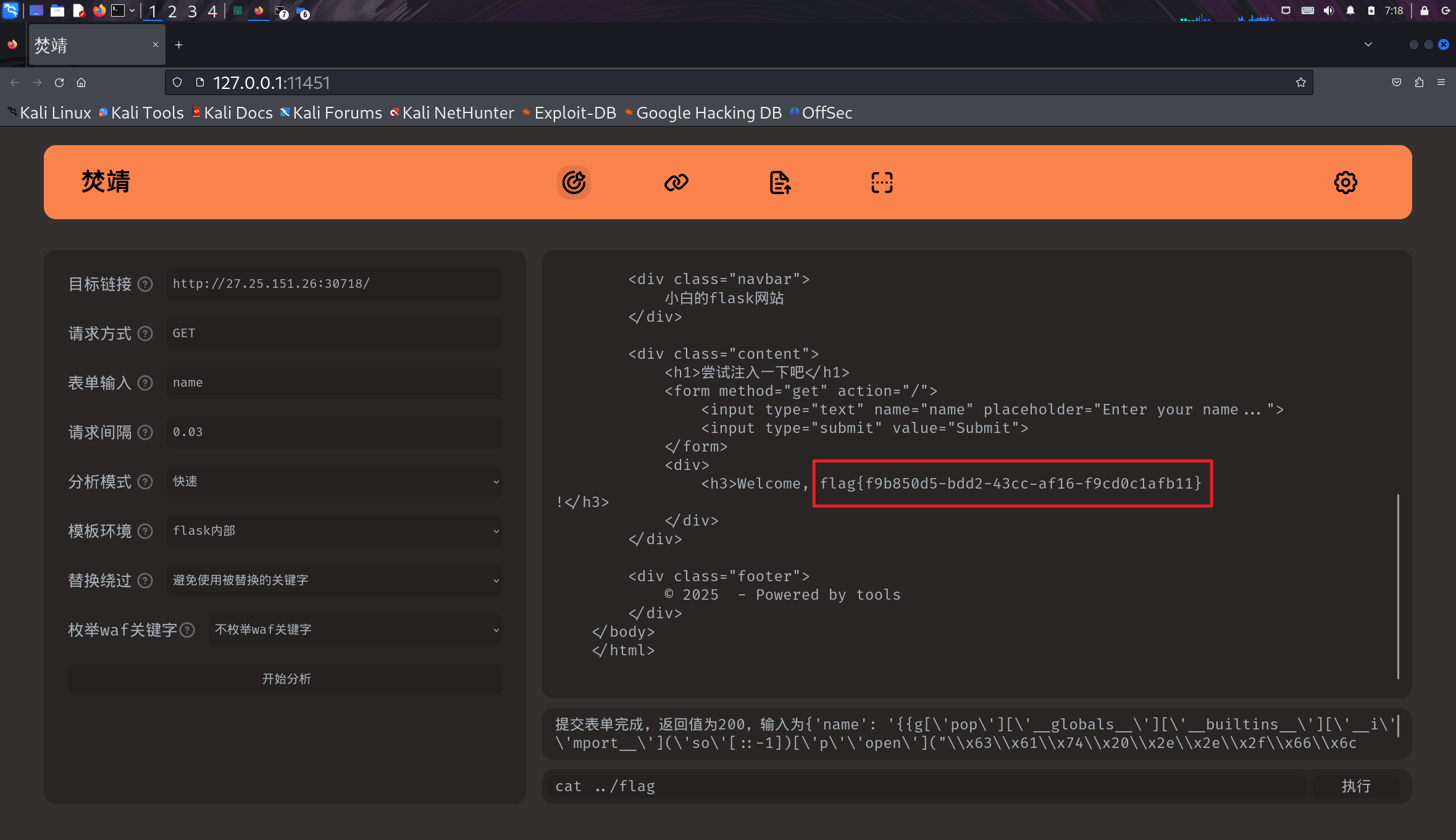
ezflask
fenjing一把梭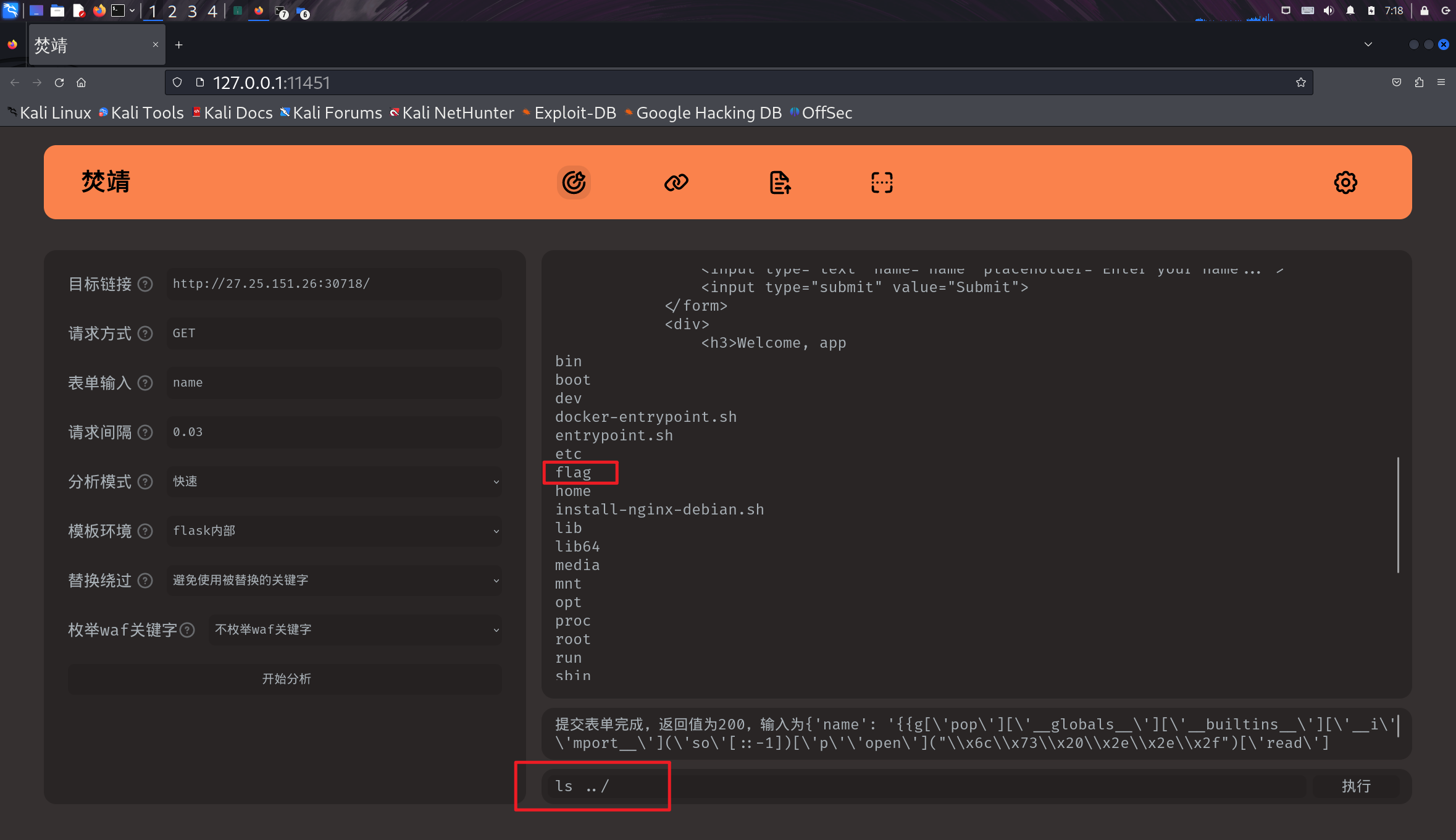
ezssrf
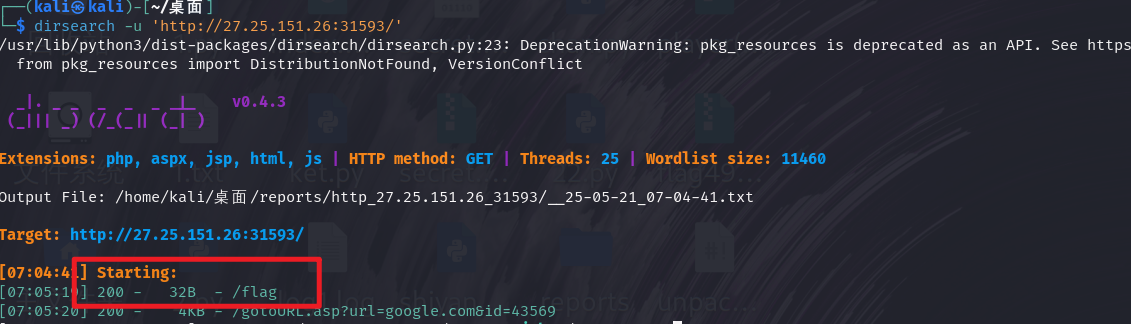
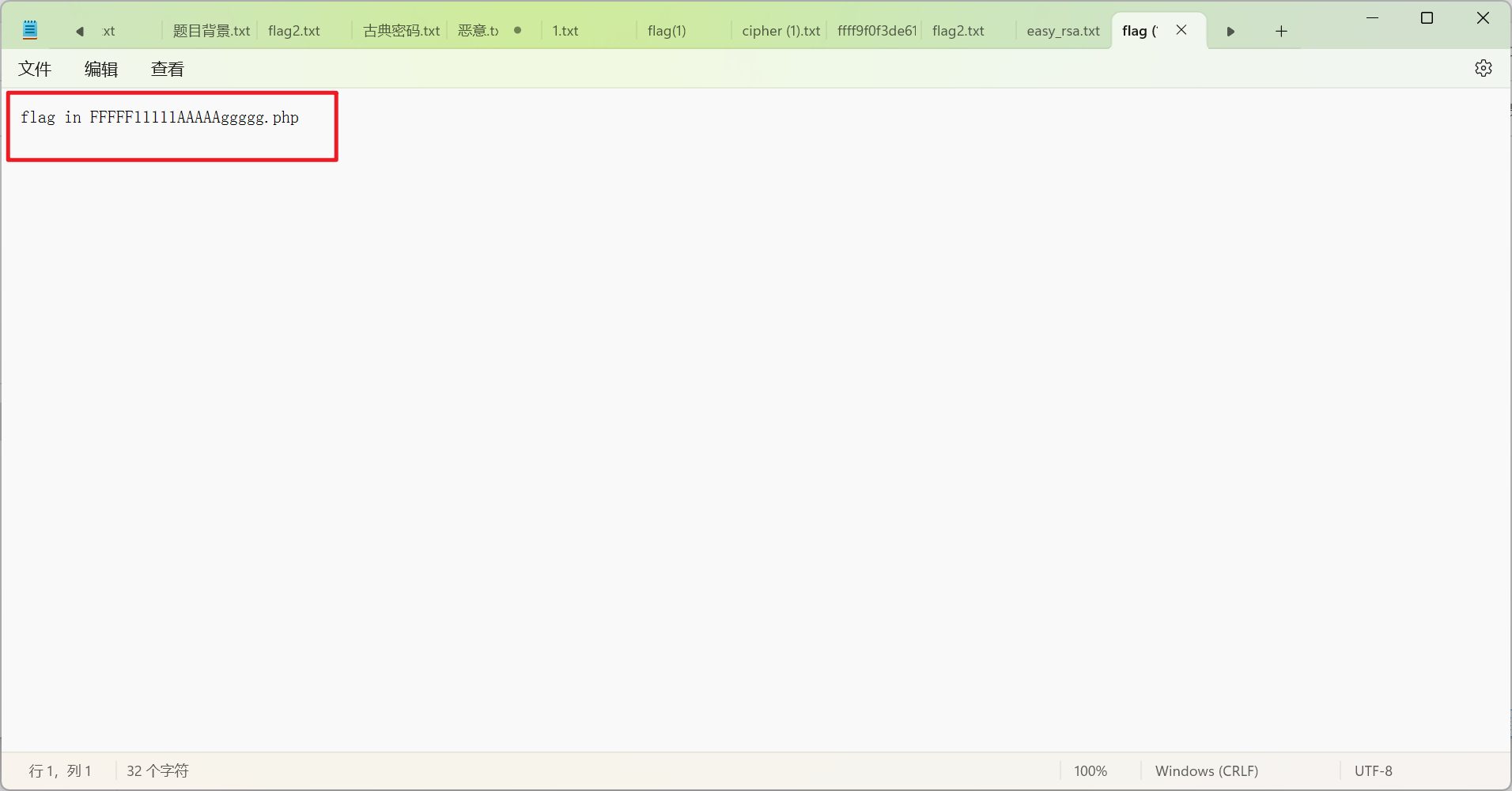
dirsearch扫描发现有/flag可访问,得到一个hint,访问即可